Analytics with ClickHouse
This feature allows exporting information about channel publications, client connections, channel subscriptions, client operations and push notifications to ClickHouse, providing an integration with a real-time (with seconds delay) analytics storage. ClickHouse is super fast for analytical queries, simple to operate with, and it allows effective data keeping for a window of time. Also, it's relatively simple to create a high-performance ClickHouse cluster.
This unlocks a great observability and a way to perform various analytics queries for better connection behavior understanding, check application correctness, building trends, reports, and so on.
As soon as you start using the integration with ClickHouse, some of the mentioned possibilities may be easily accessed with the Centrifugo PRO web UI and its analytics page:
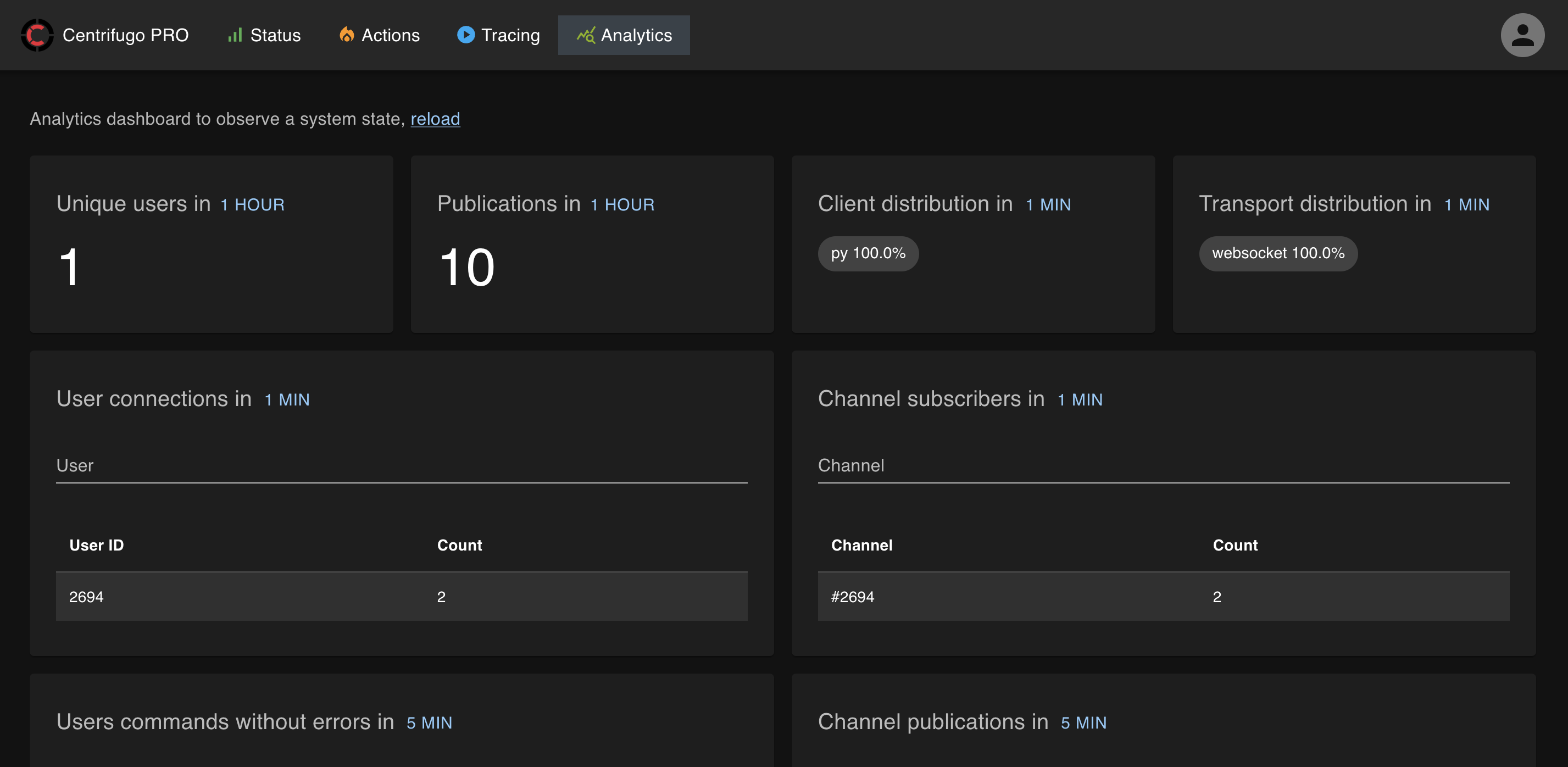
The admin UI builds ready-to-use dashboards on top of this data — Trends, User and Channel explorers, and an experimental Flight recorder. See Analytics dashboards for a tour of these views; the rest of this page documents the underlying data export, schema, and configuration.
Configuration
To enable integration with ClickHouse add the following section to a configuration file:
{
"clickhouse_analytics": {
"enabled": true,
"clickhouse_dsn": [
"tcp://127.0.0.1:9000",
"tcp://127.0.0.1:9001",
"tcp://127.0.0.1:9002",
"tcp://127.0.0.1:9003"
],
"clickhouse_database": "centrifugo",
"clickhouse_cluster": "centrifugo_cluster",
"export": {
"connections": {
"enabled": true,
"http_headers": [
"User-Agent",
"Origin",
"X-Real-Ip"
]
},
"subscriptions": {
"enabled": true
},
"operations": {
"enabled": true
},
"publications": {
"enabled": true
},
"notifications": {
"enabled": true
}
}
}
}
Centrifugo PRO supports data export only over ClickHouse native TCP protocol these days.
All ClickHouse analytics options are scoped to the clickhouse_analytics section of the configuration.
Toggle this feature using clickhouse_analytics.enabled boolean option.
Centrifugo can export data to different ClickHouse instances, addresses of ClickHouse can be set over clickhouse_analytics.clickhouse_dsn option.
You also need to set a ClickHouse cluster name (clickhouse_analytics.clickhouse_cluster) and database name clickhouse_analytics.clickhouse_database.
clickhouse_analytics.skip_schema_initialization - boolean, default false. By default Centrifugo tries to initialize table schema on start (if not exists). This flag allows skipping initialization process.
clickhouse_analytics.skip_ping_on_start - boolean, default false. Centrifugo pings ClickHouse servers by default on start; if any server is unavailable – Centrifugo fails to start. This option allows skipping this check, so Centrifugo is able to start even if the ClickHouse cluster is not working correctly.
clickhouse_analytics.tls - TLS object (available since v6.6.4). By default, no TLS is used. When enabled, TLS is applied to both data export and query connections to ClickHouse.
The export section allows configuring which data to export to ClickHouse:
clickhouse_analytics.export.connections.enabled– enables exporting connection information.clickhouse_analytics.export.subscriptions.enabled– enables exporting subscription information.clickhouse_analytics.export.operations.enabled– enables exporting individual client operation information.clickhouse_analytics.export.publications.enabled– enables exporting publications for channels.clickhouse_analytics.export.notifications.enabled– enables exporting push notifications.
Additionally:
clickhouse_analytics.export.connections.http_headersis a list of HTTP headers to export for connection information.clickhouse_analytics.export.connections.grpc_metadatais a list of metadata keys to export for connection information for GRPC unidirectional transport.clickhouse_analytics.export.connections.export_users- list of strings. Optionexport_usersis a list of users for which Centrifugo will export connections data to ClickHouse. If not set, all users will be exported. Allows enabling ClickHouse analytics for a subset of users which is generally simpler/safer/more effective than enabling connections analytics for all users.clickhouse_analytics.export.subscriptions.export_users- list of strings. Optionexport_usersis a list of users for which Centrifugo will export subscriptions data to ClickHouse. If not set, all users will be exported. Allows enabling ClickHouse analytics for a subset of users which is generally simpler/safer/more effective than enabling subscriptions analytics for all users.clickhouse_analytics.export.operations.export_users- list of strings. Optionexport_usersis a list of users for which Centrifugo will export operations data to ClickHouse. If not set, all users will be exported. Allows enabling ClickHouse analytics for a subset of users which is generally simpler/safer/more effective than enabling operations analytics for all users.clickhouse_analytics.export.publications.export_channels- list of strings. Optionexport_channelsis a list of channels for which Centrifugo will export publications data to ClickHouse. If not set, all channels will be exported. Allows enabling ClickHouse analytics for a subset of channels which is generally simpler/safer/more effective than enabling publications analytics for all channels.
DSN format
The clickhouse_dsn values use the following format:
tcp://user:password@host:port
Examples:
tcp://127.0.0.1:9000– connect with defaultstcp://user:pass@127.0.0.1:9000– connect with credentials
Per-export tuning options
Each export type (connections, subscriptions, operations, publications, notifications) supports the following tuning options:
max_buffer_size– maximum number of events to buffer in memory, default1000000. Events are dropped when the buffer is full.flush_interval– interval between flush attempts, default"10s".flush_size– maximum batch size per flush, default100000.ttl– ClickHouse table TTL for thetimecolumn, default"7 DAY".
Example:
"export": {
"connections": {
"enabled": true,
"max_buffer_size": 500000,
"flush_interval": "5s",
"flush_size": 50000,
"ttl": "30 DAY"
}
}
Retention for trend ranges
The admin UI Trends tab can show ranges up to 30 days, but it can only display data that ClickHouse still retains. The default per-export ttl is "7 DAY", so out of the box a 30‑day trend range will simply show the last 7 days and gaps before that.
To use longer trend ranges, raise the ttl for the relevant exports (e.g. "30 DAY") before the period you want to query — raising the TTL does not bring back already‑expired rows; it only changes retention going forward.
For an existing deployment, also extend the TTL on the live tables (metadata‑only change; ClickHouse drops expired rows lazily on merge):
ALTER TABLE centrifugo.connections MODIFY TTL time + INTERVAL 30 DAY;
ALTER TABLE centrifugo.subscriptions MODIFY TTL time + INTERVAL 30 DAY;
ALTER TABLE centrifugo.operations MODIFY TTL time + INTERVAL 30 DAY;
ALTER TABLE centrifugo.publications MODIFY TTL time + INTERVAL 30 DAY;
ALTER TABLE centrifugo.notifications MODIFY TTL time + INTERVAL 30 DAY;
For a cluster, add ON CLUSTER 'your_cluster' and apply the same to the _distributed tables. Longer retention means more stored data — see storage cost considerations; the dominant tables are subscriptions, connections, and operations.
Snapshots TTL
When snapshots are enabled (clickhouse_analytics.snapshots.enabled), snapshot data in ClickHouse expires after a configurable period. Use clickhouse_analytics.snapshots.ttl to control this, default is "14 DAY".
Connections table
SHOW CREATE TABLE centrifugo.connections;
┌─statement───────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.connections
(
`client` String,
`user` String,
`name` String,
`version` String,
`transport` String,
`headers` Map(String, Array(String)),
`metadata` Map(String, Array(String)),
`labels` Map(String, String),
`latency` Int64,
`node` String,
`protocol` String,
`connected_at` DateTime,
`time` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}/{shard}/connections', '{replica}')
PARTITION BY toYYYYMMDD(time)
ORDER BY time
TTL time + toIntervalDay(7)
SETTINGS index_granularity = 8192 │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
And distributed one:
SHOW CREATE TABLE centrifugo.connections_distributed;
┌─statement───────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.connections_distributed
(
`client` String,
`user` String,
`name` String,
`version` String,
`transport` String,
`headers` Map(String, Array(String)),
`metadata` Map(String, Array(String)),
`labels` Map(String, String),
`latency` Int64,
`node` String,
`protocol` String,
`connected_at` DateTime,
`time` DateTime
)
ENGINE = Distributed('centrifugo_cluster', 'centrifugo', 'connections', murmurHash3_64(client)) │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
The labels column carries client labels attached to the connection. The node column is the ID of the Centrifugo node the connection lives on, protocol is the client protocol (json/protobuf), and connected_at is when the connection was established. See Migration below for the one-time ALTERs that add these columns to existing deployments (applied automatically by default).
Subscriptions table
SHOW CREATE TABLE centrifugo.subscriptions
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.subscriptions
(
`client` String,
`user` String,
`channel` String,
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(time)
ORDER BY time
TTL time + toIntervalDay(7)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
And distributed one:
SHOW CREATE TABLE centrifugo.subscriptions_distributed;
┌─statement───────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.subscriptions_distributed
(
`client` String,
`user` String,
`channel` String,
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = Distributed('centrifugo_cluster', 'centrifugo', 'subscriptions', murmurHash3_64(client)) │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
There is one row per subscription (a single client↔channel pair) — a client subscribed to many channels produces many rows. The namespace column is the resolved channel namespace (low cardinality), always populated at export time.
Operations table
SHOW CREATE TABLE centrifugo.operations;
┌─statement─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────��─────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.operations
(
`client` String,
`user` String,
`op` String,
`channel` String,
`method` String,
`error` UInt32,
`disconnect` UInt32,
`duration` UInt64,
`labels` Map(String, String),
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}/{shard}/operations', '{replica}')
PARTITION BY toYYYYMMDD(time)
ORDER BY time
TTL time + toIntervalDay(7)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
And distributed one:
SHOW CREATE TABLE centrifugo.operations_distributed;
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.operations_distributed
(
`client` String,
`user` String,
`op` String,
`channel` String,
`method` String,
`error` UInt32,
`disconnect` UInt32,
`duration` UInt64,
`labels` Map(String, String),
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = Distributed('centrifugo_cluster', 'centrifugo', 'operations', murmurHash3_64(client)) │
└─────────────────────────────────────────────────────────────────────────────�───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Publications table
SHOW CREATE TABLE centrifugo.publications
┌─statement───────────────────────────────────────────────────────────────��───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.publications
(
`uid` String,
`channel` String,
`source` String,
`size` UInt64,
`client` String,
`user` String,
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(time)
ORDER BY time
TTL time + toIntervalDay(7)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
And distributed one:
SHOW CREATE TABLE centrifugo.publications_distributed;
┌─statement────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────�──────────────────────────────────────┐
│ CREATE TABLE centrifugo.publications_distributed
(
`uid` String,
`channel` String,
`source` String,
`size` UInt64,
`client` String,
`user` String,
`namespace` String,
`node` String,
`time` DateTime
)
ENGINE = Distributed('centrifugo_cluster', 'centrifugo', 'publications', murmurHash3_64(channel)) │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Notifications table
SHOW CREATE TABLE centrifugo.notifications
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.notifications
(
`uid` String,
`provider` String,
`type` String,
`recipient` String,
`device_id` String,
`platform` String,
`user` String,
`msg_id` String,
`status` String,
`error_message` String,
`error_code` String,
`time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(time)
ORDER BY time
TTL time + toIntervalDay(7)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
And distributed one:
SHOW CREATE TABLE centrifugo.notifications_distributed;
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE centrifugo.notifications_distributed
(
`uid` String,
`provider` String,
`type` String,
`recipient` String,
`device_id` String,
`platform` String,
`user` String,
`msg_id` String,
`status` String,
`error_message` String,
`error_code` String,
`time` DateTime
)
ENGINE = Distributed('centrifugo_cluster', 'centrifugo', 'notifications', murmurHash3_64(uid)) │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────�───────────────────────────────────────────────────────────────────────────────────────────────────┘
Snapshot tables
When clickhouse_analytics.snapshots.enabled is set, two additional tables are created for point-in-time snapshots created via the admin connections snapshot endpoint:
snapshot_channels— one row per (snapshot_id, channel, node).snapshot_connections— one row per (snapshot_id, client). Includes the samelabels Map(String, String)column as the connections table. The snapshot create API accepts alabel_filterargument; matching is applied at gather time on each node's hub, so the table only ever stores the filtered subset.
Query examples
Show unique users which were connected:
SELECT DISTINCT user
FROM centrifugo.connections_distributed;
┌─user─────┐
│ user_1 │
│ user_2 │
│ user_3 │
│ user_4 │
│ user_5 │
└──────────┘
Show total number of publication attempts which were throttled by Centrifugo (received Too many requests error with code 111):
SELECT COUNT(*)
FROM centrifugo.operations_distributed
WHERE (error = 111) AND (op = 'publish');
┌─count()─┐
│ 4502 │
└─────────┘
The same for a specific user:
SELECT COUNT(*)
FROM centrifugo.operations_distributed
WHERE (error = 111) AND (op = 'publish') AND (user = 'user_200');
┌─count()─┐
│ 1214 │
└─────────┘
Show the number of unique users subscribed to a specific channel in the last 5 minutes (this is approximate since the subscriptions table contains periodic snapshot entries; clients could unsubscribe between snapshots – this is reflected in the operations table):
SELECT uniqExact(user)
FROM centrifugo.subscriptions_distributed
WHERE (channel = 'chat:index') AND (time >= (now() - toIntervalMinute(5)));
┌─uniqExact(user)─┐
│ 101 │
└─────────────────┘
Show top 10 users which called publish operation during last one minute:
SELECT
COUNT(op) AS num_ops,
user
FROM centrifugo.operations_distributed
WHERE (op = 'publish') AND (time >= (now() - toIntervalMinute(1)))
GROUP BY user
ORDER BY num_ops DESC
LIMIT 10;
┌─num_ops─┬─user─────┐
│ 56 │ user_200 │
│ 11 │ user_75 │
│ 6 │ user_87 │
│ 6 │ user_65 │
│ 6 │ user_39 │
│ 5 │ user_28 │
│ 5 │ user_63 │
│ 5 │ user_89 │
│ 3 │ user_32 │
│ 3 │ user_52 │
└─────────┴──────────┘
Show total number of push notifications to iOS devices sent during last 24 hours:
SELECT COUNT(*)
FROM centrifugo.notifications
WHERE (time > (now() - toIntervalHour(24))) AND (platform = 'ios')
┌─count()─┐
│ 31200 │
└─────────┘
Development
The recommended way to run ClickHouse in production is with cluster. See an example of such cluster configuration made with Docker Compose.
But during development you may want to run Centrifugo with a single ClickHouse instance.
To do this, set only one ClickHouse DSN and do not set a cluster name:
{
...
"clickhouse_analytics": {
"enabled": true,
"clickhouse_dsn": [
"tcp://127.0.0.1:9000"
],
"clickhouse_database": "centrifugo",
"export": {
"connections": {
"enabled": true,
"http_headers": [
"Origin",
"User-Agent"
]
},
"subscriptions": {
"enabled": true
},
"operations": {
"enabled": true
},
"publications": {
"enabled": true
}
}
}
}
Run ClickHouse locally:
docker run -it --rm -v /tmp/clickhouse:/var/lib/clickhouse -p 9000:9000 --name click clickhouse/clickhouse-server
Run ClickHouse client:
docker run -it --rm --link click:clickhouse-server --entrypoint clickhouse-client clickhouse/clickhouse-server --host clickhouse-server
Issue queries:
:) SELECT * FROM centrifugo.operations
┌─client───────────────────────────────┬─user─┬─op──────────┬─channel─────┬─method─┬─error─┬─disconnect─┬─duration─┬────────────────time─┐
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ connecting │ │ │ 0 │ 0 │ 217894 │ 2021-07-31 08:15:09 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ connect │ │ │ 0 │ 0 │ 0 │ 2021-07-31 08:15:09 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ subscribe │ $chat:index │ │ 0 │ 0 │ 92714 │ 2021-07-31 08:15:09 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ presence │ $chat:index │ │ 0 │ 0 │ 3539 │ 2021-07-31 08:15:09 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ subscribe │ test1 │ │ 0 │ 0 │ 2402 │ 2021-07-31 08:15:12 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ subscribe │ test2 │ │ 0 │ 0 │ 634 │ 2021-07-31 08:15:12 │
│ bd55ae3a-dd44-47cb-a4cc-c41f8e33803b │ 2694 │ subscribe │ test3 │ │ 0 │ 0 │ 412 │ 2021-07-31 08:15:12 │
└──────────────────────────────────────┴──────┴─────────────┴─────────────┴────────┴───────┴────────────┴──────────┴─────────────────────┘
How export works
When ClickHouse analytics is enabled, Centrifugo nodes start exporting events to ClickHouse. Each node issues an insert with events once every 10 seconds (flushing collected events in batches, thus making insertion into ClickHouse efficient). The maximum batch size is 100k for each table at the moment. If an insert to ClickHouse fails, Centrifugo retries it once and then buffers events in memory (up to 1 million entries). If ClickHouse is still unavailable after collecting 1 million events, new events will be dropped until the buffer has space. These limits are configurable. Centrifugo PRO uses very efficient code for writing data to ClickHouse, so the analytics feature should only add a little overhead for a Centrifugo node.
Exposed metrics
Several metrics are exposed to monitor export process health:
centrifugo_clickhouse_analytics_drop_count
- Type: Counter
- Labels: type
- Description: Total count of drops.
- Usage: Useful for tracking the number of data drops in ClickHouse analytics, helping identify potential issues with data processing.
centrifugo_clickhouse_analytics_flush_duration_seconds
- Type: Summary
- Labels: type, retries, result
- Description: Duration of ClickHouse data flush in seconds.
- Usage: Helps in monitoring the performance of data flush operations in ClickHouse, aiding in performance tuning and issue resolution.
centrifugo_clickhouse_analytics_batch_size
- Type: Summary
- Labels: type
- Description: Distribution of batch sizes for ClickHouse flush.
- Usage: Useful for understanding the size of data batches being flushed to ClickHouse, helping optimize performance.
Migration
Release v6.8.2 added several columns across the analytics tables:
| New column | Tables | Purpose |
|---|---|---|
labels Map(String, String) | connections, operations, snapshot_connections | Client labels on the connection |
namespace String | operations, publications, subscriptions | Low-cardinality channel namespace, always resolved at export time |
channel String | subscriptions | Per-subscription channel — the table is now one row per subscription |
latency Int64 | connections | Client ping/pong RTT (ns) — powers the Connection latency p95 trend |
node String | connections, operations, publications, subscriptions | ID of the Centrifugo node — per-node breakdowns & load-imbalance detection |
protocol String | connections | Client protocol (json/protobuf) — protocol-mix breakdowns |
connected_at DateTime | connections | When the connection was established — connection age / session duration |
When Centrifugo manages the ClickHouse schema — the default, clickhouse_analytics.skip_schema_initialization is false — it adds these columns automatically on start, the same way it creates missing tables. The ALTERs are metadata-only (no data rewrite, fast even on large tables) and idempotent, so an upgrade just works with no manual step.
You only need the manual SQL below when:
- you run with
clickhouse_analytics.skip_schema_initialization: true(you manage the schema yourself), or - the ClickHouse user Centrifugo connects with lacks
ALTERprivilege.
In both cases Centrifugo's startup probe still refuses to start with an actionable error listing the exact statements to run, so you can never run against a stale schema.
Manual migration
Only needed for the two cases above — run before starting the new binary.
Standalone ClickHouse — run all statements (replace centrifugo with your clickhouse_database if it differs; skip any line for a table whose ingestion you have not enabled — the probe only checks enabled tables):
-- connections: client labels + latency + node + protocol + connected_at
ALTER TABLE centrifugo.connections ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.connections ADD COLUMN IF NOT EXISTS latency Int64 DEFAULT 0;
ALTER TABLE centrifugo.connections ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.connections ADD COLUMN IF NOT EXISTS protocol String DEFAULT '';
ALTER TABLE centrifugo.connections ADD COLUMN IF NOT EXISTS connected_at DateTime DEFAULT toDateTime(0);
-- operations: client labels + channel namespace + node
ALTER TABLE centrifugo.operations ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.operations ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.operations ADD COLUMN IF NOT EXISTS node String DEFAULT '';
-- publications: channel namespace + node
ALTER TABLE centrifugo.publications ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.publications ADD COLUMN IF NOT EXISTS node String DEFAULT '';
-- subscriptions: channel namespace + per-subscription channel + node
ALTER TABLE centrifugo.subscriptions ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.subscriptions ADD COLUMN IF NOT EXISTS channel String DEFAULT '';
ALTER TABLE centrifugo.subscriptions ADD COLUMN IF NOT EXISTS node String DEFAULT '';
-- snapshot_connections: client labels
ALTER TABLE centrifugo.snapshot_connections ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ClickHouse cluster — add ON CLUSTER 'centrifugo_cluster' (use your clickhouse_cluster value) to every statement above, and apply the same additions to the _distributed companion tables so distributed inserts succeed:
-- local (Replicated) tables
ALTER TABLE centrifugo.connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS latency Int64 DEFAULT 0;
ALTER TABLE centrifugo.connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS protocol String DEFAULT '';
ALTER TABLE centrifugo.connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS connected_at DateTime DEFAULT toDateTime(0);
ALTER TABLE centrifugo.operations ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.operations ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.operations ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.publications ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.publications ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.subscriptions ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.subscriptions ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS channel String DEFAULT '';
ALTER TABLE centrifugo.subscriptions ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.snapshot_connections ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
-- _distributed companion tables
ALTER TABLE centrifugo.connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS latency Int64 DEFAULT 0;
ALTER TABLE centrifugo.connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS protocol String DEFAULT '';
ALTER TABLE centrifugo.connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS connected_at DateTime DEFAULT toDateTime(0);
ALTER TABLE centrifugo.operations_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
ALTER TABLE centrifugo.operations_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.operations_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.publications_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.publications_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.subscriptions_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS namespace String DEFAULT '';
ALTER TABLE centrifugo.subscriptions_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS channel String DEFAULT '';
ALTER TABLE centrifugo.subscriptions_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS node String DEFAULT '';
ALTER TABLE centrifugo.snapshot_connections_distributed ON CLUSTER 'centrifugo_cluster' ADD COLUMN IF NOT EXISTS labels Map(String, String) DEFAULT map();
New deployments need no action — the CREATE TABLE IF NOT EXISTS issued on first start already includes every column above.
Downgrade stays safe — all columns have defaults (map(), '', 0, toDateTime(0)), so an older binary that omits them from INSERT VALUES keeps inserting successfully. No schema rollback needed.
Namespace resolution
The namespace column is always resolved from the channel at export time, using the same logic as Prometheus channel namespace metrics. For RPC operations (which have no channel) the namespace is resolved from the RPC method instead, using the configured rpc_namespace_boundary. No configuration is required — there is no opt-in toggle.
Subscriptions: one row per subscription
Alongside the namespace column, the subscriptions table moves to one row per subscription: the old channels Array(String) column is replaced by a scalar channel String, making it consistent with operations/publications and removing the need for ARRAY JOIN in queries.
before: client | user | channels Array(String) | time
after: client | user | channel String | namespace String | time
The ALTER above is additive — the new scalar channel is added alongside the existing channels array, which Centrifugo simply stops writing.
This is non-destructive but not retroactive. Existing rows keep their data in the old channels array with an empty scalar channel, so they will not appear in channel/namespace-based subscription views until they expire under the table TTL (default 7 days). For that TTL window after upgrade, subscription trends count only newly-exported rows — expect them to ramp up to steady state over the first TTL period. No action is needed; it self-heals as old rows age out.
The dead channels array column is harmless and ages out within the TTL. Once the migration window has fully passed you may optionally reclaim its space:
ALTER TABLE centrifugo.subscriptions DROP COLUMN IF EXISTS channels; -- optional, after the TTL window
Cardinality warning
The labels column is a Map(String, String) — every unique label key/value combination adds to the column's dictionary. Putting unbounded values into labels (session IDs, request IDs, user IDs) bloats the column and degrades compression. The same concern applies to the Prometheus dimensions exported via prometheus.client_labels — keep labels bounded at the source.