Engines and scalability
The Engine in Centrifugo is responsible for publishing messages between nodes, handle PUB/SUB broker subscriptions, save/retrieve online presence and history data.
By default, Centrifugo uses a Memory engine. There are also Redis, KeyDB, Tarantool engines available. And Nats broker which also supports at most once PUB/SUB.
With default Memory engine you can start only one node of Centrifugo, while other engines allow running several nodes on different machines to scale client connections and for Centrifugo node high availability. In distributed case all Centrifugo nodes will be connected via broker PUB/SUB, will discover each other and deliver publications to the node where active channel subscribers exist.
Memory engine keeps history and presence data in process memory, so the data is lost upon server restart. When using Redis Engine the data is kept in Redis (where you can configure desired persistence properties) instead of Centrifugo node process memory, so channel history data won't be lost after Centrifugo server restart.
To set engine you can use engine configuration option. Available values are memory, redis, tarantool. The default value is memory.
For example to work with Redis engine:
{
...
"engine": "redis"
}
Memory engine
Used by default. Supports only one node. Nice choice to start with. Supports all features keeping everything in Centrifugo node process memory. You don't need to install Redis when using this engine.
Advantages:
- Super fast since it does not involve network at all
- Does not require separate broker setup
Disadvantages:
- Does not allow scaling nodes (actually you still can scale Centrifugo with Memory engine but you have to publish data into each Centrifugo node and you won't have consistent history and presence state throughout Centrifugo nodes)
- Does not persist message history in channels between Centrifugo restarts.
Memory engine options
history_meta_ttl
Duration, default 2160h (90 days).
history_meta_ttl sets a time of history stream metadata expiration.
When using a history in a channel, Centrifugo keeps some metadata for it. Metadata includes the latest stream offset and its epoch value. In some cases, when channels are created for а short time and then not used anymore, created metadata can stay in memory while not useful. For example, you can have a personal user channel but after using your app for a while user left it forever. From a long-term perspective, this can be an unwanted memory growth. Setting a reasonable value to this option can help to expire metadata faster (or slower if you need it). The rule of thumb here is to keep this value much bigger than maximum history TTL used in Centrifugo configuration.
Redis engine
Redis is an open-source, in-memory data structure store, used as a database, cache, and message broker.
Centrifugo Redis engine allows scaling Centrifugo nodes to different machines. Nodes will use Redis as a message broker (utilizing Redis PUB/SUB for node communication) and keep presence and history data in Redis.
Minimal Redis version is 5.0.1
With Redis it's possible to come to the architecture like this:
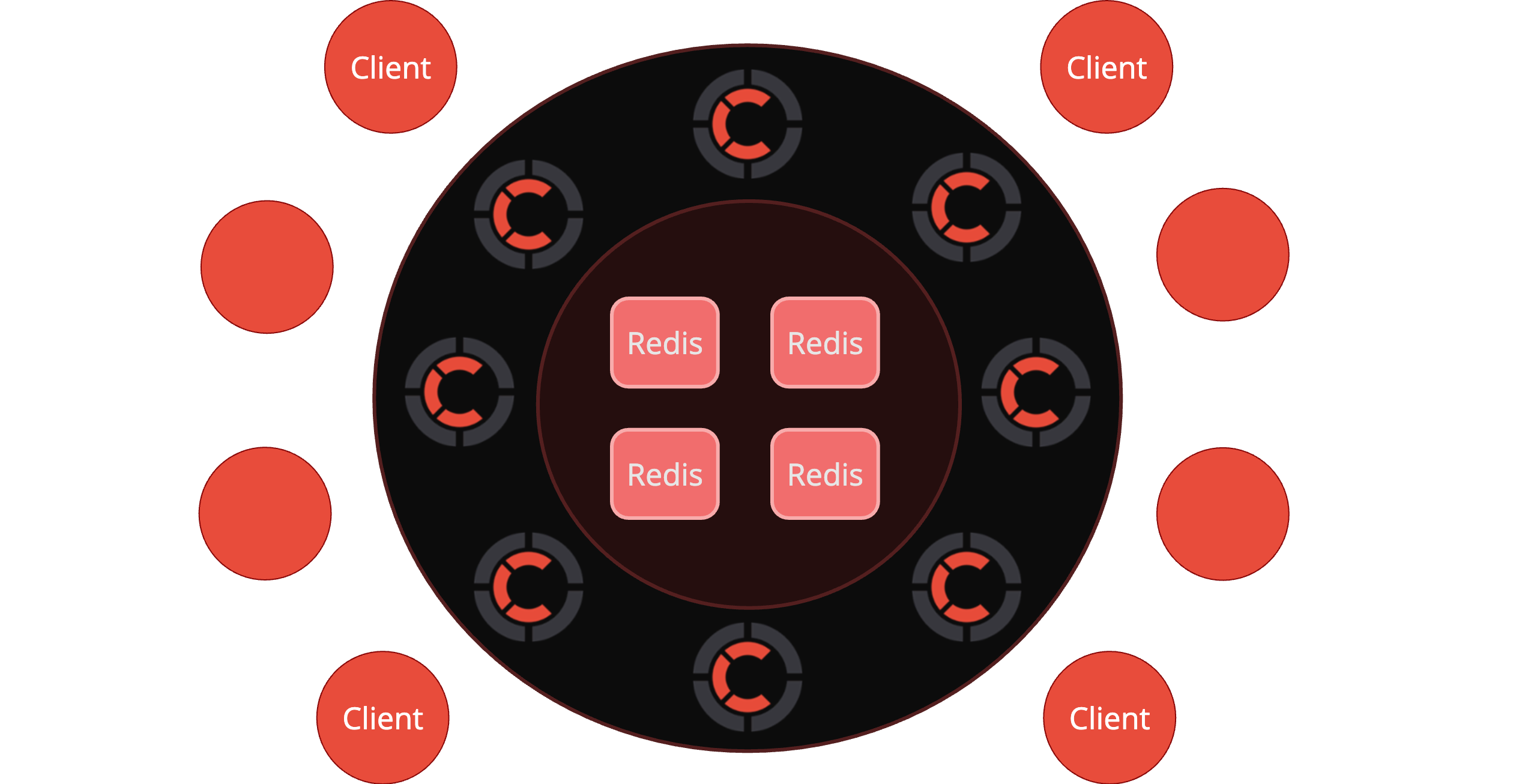
Redis engine options
Several configuration options related to Redis engine.
redis_address
String, default "127.0.0.1:6379" - Redis server address.
redis_password
String, default "" - Redis password.
redis_user
String, default "" - Redis user for ACL-based auth.
redis_db
Integer, default 0 - number of Redis db to use.
redis_prefix
String, default "centrifugo" – custom prefix to use for channels and keys in Redis.
redis_use_lists
Boolean, default false – turns on using Redis Lists instead of Stream data structure for keeping history (not recommended, keeping this for backwards compatibility mostly).
redis_force_resp2
Available since Centrifugo v4.1.3
Boolean, default false. If set to true it forces using RESP2 protocol for communicating with Redis. By default, Redis client used by Centrifugo tries to detect supported Redis protocol automatically trying RESP3 first.
history_meta_ttl
Duration, default 2160h (90 days).
history_meta_ttl sets a time of history stream metadata expiration.
Similar to a Memory engine Redis engine also looks at history_meta_ttl option. Meta key in Redis is a HASH that contains the current offset number in channel and the stream epoch value.
When using a history in a channel, Centrifugo saves metadata for it. Metadata includes the latest stream offset and its epoch value. In some cases, when channels are created for а short time and then not used anymore, created metadata can stay in memory while not useful. For example, you can have a personal user channel but after using your app for a while user left it forever. From a long-term perspective, this can be an unwanted memory growth. Setting a reasonable value to this option can help. The rule of thumb here is to keep this value much bigger than maximum history TTL used in Centrifugo configuration.
Configuring Redis TLS
Some options may help you configuring TLS-protected communication between Centrifugo and Redis.
redis_tls
Boolean, default false - enable Redis TLS connection.
redis_tls_insecure_skip_verify
Boolean, default false - disable Redis TLS host verification. Centrifugo v4 also supports alias for this option – redis_tls_skip_verify – but it will be removed in v5.
redis_tls_cert
Added in Centrifugo v4.1.0
String, default "" – path to TLS cert file. If you prefer passing certificate as a string instead of path to the file then use redis_tls_cert_pem option.
redis_tls_key
Added in Centrifugo v4.1.0
String, default "" – path to TLS key file. If you prefer passing cert key as a string instead of path to the file then use redis_tls_key_pem option.
redis_tls_root_ca
Added in Centrifugo v4.1.0
String, default "" – path to TLS root CA file (in PEM format) to use. If you prefer passing root CA PEM as a string instead of path to the file then use redis_tls_root_ca_pem option.
redis_tls_server_name
Added in Centrifugo v4.1.0
String, default "" – used to verify the hostname on the returned certificates. It is also included in the client's handshake to support virtual hosting unless it is an IP address.
Scaling with Redis tutorial
Let's see how to start several Centrifugo nodes using the Redis Engine. We will start 3 Centrifugo nodes and all those nodes will be connected via Redis.
First, you should have Redis running. As soon as it's running - we can launch 3 Centrifugo instances. Open your terminal and start the first one:
centrifugo --config=config.json --port=8000 --engine=redis --redis_address=127.0.0.1:6379
If your Redis is on the same machine and runs on its default port you can omit redis_address option in the command above.
Then open another terminal and start another Centrifugo instance:
centrifugo --config=config.json --port=8001 --engine=redis --redis_address=127.0.0.1:6379
Note that we use another port number (8001) as port 8000 is already busy by our first Centrifugo instance. If you are starting Centrifugo instances on different machines then you most probably can use
the same port number (8000 or whatever you want) for all instances.
And finally, let's start the third instance:
centrifugo --config=config.json --port=8002 --engine=redis --redis_address=127.0.0.1:6379
Now you have 3 Centrifugo instances running on ports 8000, 8001, 8002 and clients can connect to any of them. You can also send API requests to any of those nodes – as all nodes connected over Redis PUB/SUB message will be delivered to all interested clients on all nodes.
To load balance clients between nodes you can use Nginx – you can find its configuration here in the documentation.
In the production environment you will most probably run Centrifugo nodes on different hosts, so there will be no need to use different port numbers.
Here is a live example where we locally start two Centrifugo nodes both connected to local Redis:
Redis Sentinel for high availability
Centrifugo supports the official way to add high availability to Redis - Redis Sentinel.
For this you only need to utilize 2 Redis Engine options: redis_sentinel_address and redis_sentinel_master_name:
redis_sentinel_address(string, default"") - comma separated list of Sentinel addresses for HA. At least one known server required.redis_sentinel_master_name(string, default"") - name of Redis master Sentinel monitors
Also:
redis_sentinel_password– optional string password for your Sentinel, works with Redis Sentinel >= 5.0.1redis_sentinel_user- optional string user (used only in Redis ACL-based auth).
So you can start Centrifugo which will use Sentinels to discover Redis master instances like this:
centrifugo --config=config.json
Where config.json:
{
...
"engine": "redis",
"redis_sentinel_address": "127.0.0.1:26379",
"redis_sentinel_master_name": "mymaster"
}
Sentinel configuration file may look like this (for 3-node Sentinel setup with quorum 2):
port 26379
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 10000
sentinel failover-timeout mymaster 60000
You can find how to properly set up Sentinels in official documentation.
Note that when your Redis master instance is down there will be a small downtime interval until Sentinels discover a problem and come to a quorum decision about a new master. The length of this period depends on Sentinel configuration.
Redis Sentinel TLS
To configure TLS for Redis Sentinel use the following options.
redis_sentinel_tls
Boolean, default false - enable Redis TLS connection.
redis_sentinel_tls_insecure_skip_verify
Boolean, default false - disable Redis TLS host verification. Centrifugo v4 also supports alias for this option – redis_sentinel_tls_skip_verify – but it will be removed in v5.
redis_sentinel_tls_cert
Added in Centrifugo v4.1.0
String, default "" – path to TLS cert file. If you prefer passing certificate as a string instead of path to the file then use redis_sentinel_tls_cert_pem option.
redis_sentinel_tls_key
Added in Centrifugo v4.1.0
String, default "" – path to TLS key file. If you prefer passing cert key as a string instead of path to the file then use redis_sentinel_tls_key_pem option.
redis_sentinel_tls_root_ca
Added in Centrifugo v4.1.0
String, default "" – path to TLS root CA file (in PEM format) to use. If you prefer passing root CA PEM as a string instead of path to the file then use redis_sentinel_tls_root_ca_pem option.
redis_sentinel_tls_server_name
Added in Centrifugo v4.1.0
String, default "" – used to verify the hostname on the returned certificates. It is also included in the client's handshake to support virtual hosting unless it is an IP address.
Haproxy instead of Sentinel configuration
Alternatively, you can use Haproxy between Centrifugo and Redis to let it properly balance traffic to Redis master. In this case, you still need to configure Sentinels but you can omit Sentinel specifics from Centrifugo configuration and just use Redis address as in a simple non-HA case.
For example, you can use something like this in Haproxy config:
listen redis
server redis-01 127.0.0.1:6380 check port 6380 check inter 2s weight 1 inter 2s downinter 5s rise 10 fall 2
server redis-02 127.0.0.1:6381 check port 6381 check inter 2s weight 1 inter 2s downinter 5s rise 10 fall 2 backup
bind *:16379
mode tcp
option tcpka
option tcplog
option tcp-check
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
balance roundrobin
And then just point Centrifugo to this Haproxy:
centrifugo --config=config.json --engine=redis --redis_address="localhost:16379"
Redis sharding
Centrifugo has built-in Redis sharding support.
This resolves the situation when Redis becoming a bottleneck on a large Centrifugo setup. Redis is a single-threaded server, it's very fast but its power is not infinite so when your Redis approaches 100% CPU usage then the sharding feature can help your application to scale.
At moment Centrifugo supports a simple comma-based approach to configuring Redis shards. Let's just look at examples.
To start Centrifugo with 2 Redis shards on localhost running on port 6379 and port 6380 use config like this:
{
...
"engine": "redis",
"redis_address": [
"127.0.0.1:6379",
"127.0.0.1:6380",
]
}
To start Centrifugo with Redis instances on different hosts:
{
...
"engine": "redis",
"redis_address": [
"192.168.1.34:6379",
"192.168.1.35:6379",
]
}
If you also need to customize AUTH password, Redis DB number then you can use an extended address notation.
Due to how Redis PUB/SUB works it's not possible (and it's pretty useless anyway) to run shards in one Redis instance using different Redis DB numbers.
When sharding enabled Centrifugo will spread channels and history/presence keys over configured Redis instances using a consistent hashing algorithm. At moment we use Jump consistent hash algorithm (see paper and implementation).
Redis cluster
Running Centrifugo with Redis cluster is simple and can be achieved using redis_cluster_address option. This is an array of strings. Each element of the array is a comma-separated Redis cluster seed node. For example:
{
...
"redis_cluster_address": [
"localhost:30001,localhost:30002,localhost:30003"
]
}
You don't need to list all Redis cluster nodes in config – only several working nodes are enough to start.
To set the same over environment variable:
CENTRIFUGO_REDIS_CLUSTER_ADDRESS="localhost:30001" CENTRIFUGO_ENGINE=redis ./centrifugo
If you need to shard data between several Redis clusters then simply add one more string with seed nodes of another cluster to this array:
{
...
"redis_cluster_address": [
"localhost:30001,localhost:30002,localhost:30003",
"localhost:30101,localhost:30102,localhost:30103"
]
}
Sharding between different Redis clusters can make sense due to the fact how PUB/SUB works in the Redis cluster. It does not scale linearly when adding nodes as all PUB/SUB messages got copied to every cluster node. See this discussion for more information on topic. To spread data between different Redis clusters Centrifugo uses the same consistent hashing algorithm described above (i.e. Jump).
To reproduce the same over environment variable use space to separate different clusters:
CENTRIFUGO_REDIS_CLUSTER_ADDRESS="localhost:30001,localhost:30002 localhost:30101,localhost:30102" CENTRIFUGO_ENGINE=redis ./centrifugo
KeyDB Engine
EXPERIMENTAL
Centrifugo Redis engine seamlessly works with KeyDB. KeyDB server is compatible with Redis and provides several additional features beyond.
We can't give any promises about compatibility with KeyDB in the future Centrifugo releases - while KeyDB is fully compatible with Redis things should work just fine. That's why we consider this as EXPERIMENTAL feature.
Use KeyDB instead of Redis only if you are sure you need it. Nothing stops you from running several Redis instances per each core you have, configure sharding, and obtain even better performance than KeyDB can provide (due to lack of synchronization between threads in Redis).
To run Centrifugo with KeyDB all you need to do is use redis engine but run the KeyDB server instead of Redis.
Other Redis compatible
Other storages which are compatible with Centrifugo may work, but we did not make enough testing with them. Some of them still evolving and do not fully support Redis protocol. So if you want to use these storages with Centrifugo – please read carefully the notes below:
- AWS Elasticache – it was reported to work, but we suggest you testing the setup including failover tests and work under load.
- DragonflyDB - it's mostly compatible, the only problem with DragonflyDB v1.0.0 we observed is failing test regarding history iteration in reversed order (not very common). We have not tested a Redis Cluster emulation mode provided by DragonflyDB yet. We suggest you testing the setup including failover tests and work under load.
Tarantool engine
EXPERIMENTAL
Tarantool is a fast and flexible in-memory storage with different persistence/replication schemes and LuaJIT for writing custom logic on the Tarantool side. It allows implementing Centrifugo engine with unique characteristics.
EXPERIMENTAL status of Tarantool integration means that we are still going to improve it and there could be breaking changes as integration evolves.
There are many ways to operate Tarantool in production and it's hard to distribute Centrifugo Tarantool engine in a way that suits everyone. Centrifugo tries to fit generic case by providing centrifugal/tarantool-centrifuge module and by providing ready-to-use centrifugal/rotor project based on centrifugal/tarantool-centrifuge and Tarantool Cartridge.
To be honest we bet on the community help to push this integration further. Tarantool provides an incredible performance boost for presence and history operations (up to 5x more RPS compared to the Redis Engine) and a pretty fast PUB/SUB (comparable to what Redis Engine provides). Let's see what we can build together.
There are several supported Tarantool topologies to which Centrifugo can connect:
- One standalone Tarantool instance
- Many standalone Tarantool instances and consistently shard data between them
- Tarantool running in Cartridge
- Tarantool with replica and automatic failover in Cartridge
- Many Tarantool instances (or leader-follower setup) in Cartridge with consistent client-side sharding between them
- Tarantool with synchronous replication (Raft-based, Tarantool >= 2.7)
After running Tarantool you can point Centrifugo to it (and of course scale Centrifugo nodes):
{
...
"engine": "tarantool",
"tarantool_address": "127.0.0.1:3301"
}
See centrifugal/rotor repo for ready-to-use engine based on Tarantool Cartridge framework.
See centrifugal/tarantool-centrifuge repo for examples on how to run engine with Standalone single Tarantool instance or with Raft-based synchronous replication.
Tarantool engine options
tarantool_address
String or array of strings. Default tcp://127.0.0.1:3301.
Connection address to Tarantool.
tarantool_mode
String, default standalone
A mode how to connect to Tarantool. Default is standalone which connects to a single Tarantool instance address. Possible values are: leader-follower (connects to a setup with Tarantool master and async replicas) and leader-follower-raft (connects to a Tarantool with synchronous Raft-based replication).
All modes support client-side consistent sharding (similar to what Redis engine provides).
tarantool_user
String, default "". Allows setting a user.
tarantool_password
String, default "". Allows setting a password.
history_meta_ttl
Duration, default 2160h.
Same option as for Memory engine and Redis engine also applies to Tarantool case.
Nats broker
It's possible to scale with Nats PUB/SUB server. Keep in mind, that Nats is called a broker here, not an Engine – Nats integration only implements PUB/SUB part of Engine, so carefully read limitations below.
Limitations:
- Nats integration works only for unreliable at most once PUB/SUB. This means that history, presence, and message recovery Centrifugo features won't be available.
- Nats wildcard channel subscriptions with symbols
*and>not supported.
First start Nats server:
$ nats-server
[3569] 2020/07/08 20:28:44.324269 [INF] Starting nats-server version 2.1.7
[3569] 2020/07/08 20:28:44.324400 [INF] Git commit [not set]
[3569] 2020/07/08 20:28:44.325600 [INF] Listening for client connections on 0.0.0.0:4222
[3569] 2020/07/08 20:28:44.325612 [INF] Server id is NDAM7GEHUXAKS5SGMA3QE6ZSO4IQUJP6EL3G2E2LJYREVMAMIOBE7JT4
[3569] 2020/07/08 20:28:44.325617 [INF] Server is ready
Then start Centrifugo with broker option:
centrifugo --broker=nats --config=config.json
And one more Centrifugo on another port (of course in real life you will start another Centrifugo on another machine):
centrifugo --broker=nats --config=config.json --port=8001
Now you can scale connections over Centrifugo instances, instances will be connected over Nats server.
Options
nats_url
String, default nats://127.0.0.1:4222.
Connection url in format nats://derek:pass@localhost:4222.
nats_prefix
String, default centrifugo.
Prefix for channels used by Centrifugo inside Nats.
nats_dial_timeout
Duration, default 1s.
Timeout for dialing with Nats.
nats_write_timeout
Duration, default 1s.
Write (and flush) timeout for a connection to Nats.