Channels and namespaces
Upon connecting to a server clients can subscribe to channels. Channel is one of the core concepts of Centrifugo. Most of the time when integrating Centrifugo you will work with channels and decide what is the best channel configuration for your application.
What is channel
Centrifugo is a PUB/SUB system - it has publishers and subscribers. Channel is a route for publications. Clients can subscribe to a channel to receive all real-time messages published to a channel. A channel subscriber can also ask for a channel online presence or channel history information.
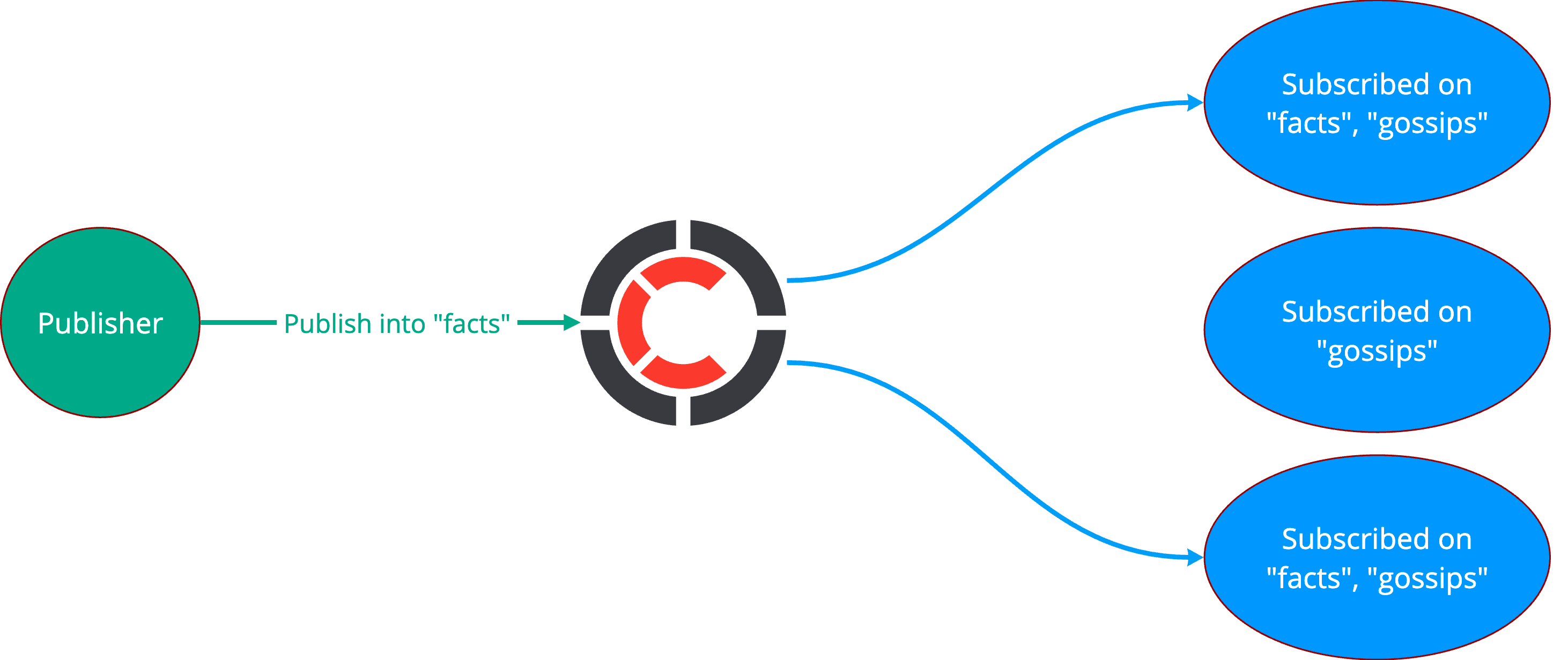
Channel is just a string - news, comments, personal_feed are valid channel names. Though this string has some predefined rules as we will see below. You can define different channel behavior using a set of available channel options.
Channels are ephemeral – you don't need to create them explicitly. Channels created automatically by Centrifugo as soon as the first client subscribes to a channel. As soon as the last subscriber leaves a channel - it's automatically cleaned up.
Channel can belong to a channel namespace. Channel namespacing is a mechanism to define different behavior for different channels in Centrifugo. Using namespaces is a recommended way to manage channels – to turn on only those channel options which are required for a specific real-time feature you are implementing on top of Centrifugo.
When using channel namespaces make sure you defined a namespace in configuration. Subscription attempts to a channel within a non-defined namespace will result into 102: unknown channel errors.
Channel name rules
Only ASCII symbols must be used in a channel string.
Channel name length limited by 255 characters by default (controlled by configuration option channel_max_length).
Several symbols in channel names reserved for Centrifugo internal needs:
:– for namespace channel boundary (see below)#– for user channel boundary (see below)$– for private channel prefix (see below)*– for the future Centrifugo needs&– for the future Centrifugo needs/– for the future Centrifugo needs
namespace boundary (:)
: – is a channel namespace boundary. Namespaces are used to set custom options to a group of channels. Each channel belonging to the same namespace will have the same channel options. Read more about about namespaces and channel options below.
If the channel is public:chat - then Centrifugo will apply options to this channel from the channel namespace with the name public.
A namespace is part of the channel name. If a user subscribed to a channel with namespace, like public:chat – then you need to publish messages into public:chat channel to be delivered to the user. We often see some confusion from developers trying to publish messages into chat and thinking that namespace is somehow stripped upon subscription. It's not true.
user channel boundary (#)
# – is a user channel boundary. This is a separator to create personal channels for users (we call this user-limited channels) without the need to provide a subscription token.
For example, if the channel is news#42 then the only user with ID 42 can subscribe to this channel (Centrifugo knows user ID because clients provide it in connection credentials with connection JWT).
If you want to create a user-limited channel in namespace personal then you can use a name like personal:user#42 for example.
Moreover, you can provide several user IDs in channel name separated by a comma: dialog#42,43 – in this case only the user with ID 42 and user with ID 43 will be able to subscribe on this channel.
This is useful for channels with a static list of allowed users, for example for single user personal messages channel, for dialog channel between certainly defined users. As soon as you need to manage access to a channel dynamically for many users this channel type does not suit well.
User-limited channels must be enabled for a channel namespace using allow_user_limited_channels option. See below more information about channel options and channel namespaces.
private channel prefix ($)
Centrifugo v4 has this option to achieve compatibility with previous Centrifugo versions. Previously (in Centrifugo v1, v2 and v3) only channels starting with $ could be subscribed with a subscription JWT. In Centrifugo v4 that's not the case anymore – clients can subscribe to any channel with a subscription token (if the token is valid – then subscription to a channel is accepted).
But for namespaces with allow_subscribe_for_client option enabled Centrifugo does not allow subscribing on channels starting with private_channel_prefix ($ by default) without a subscription token. This limitation exists to help users migrate to Centrifugo v4 without security risks.
Channel is just a string
Keep in mind that a channel is uniquely identified by its string representation. Do not expect that channels $news and news are the same. They are different because strings are not equal. So if a user subscribed to $news then user won't receive messages published to news.
Channels dialog#42,43 and dialog#43,42 are two different channels too. Centrifugo only applies permission checks when a user subscribes to a channel. So if user-limited channels are enabled then the user with ID 42 will be able to subscribe on both dialog#42,43 and dialog#43,42. But Centrifugo does no magic regarding channel strings when keeping channel->to->subscribers map. So if the user subscribed on dialog#42,43 you must publish messages to exactly that channel: dialog#42,43.
The same applies to channels with namespaces. Do not expect that channels chat:index and index are the same – they are different, moreover, belong to different namespaces. We'll look at the concept of channel namespaces in Centrifugo shortly.
Channel namespaces
It's possible to configure a list of channel namespaces. Namespaces are optional but very useful.
A namespace allows setting custom options for channels starting with the namespace name. This provides great control over channel behavior so you have a flexible way to define different channel options for different real-time features in the application.
Namespace has a name, and the same channel options (with the same defaults) as described above.
name- unique namespace name (name must consist of letters, numbers, underscores, or hyphens and be more than 2 symbols length i.e. satisfy regexp^[-a-zA-Z0-9_]{2,}$).
If you want to use namespace options for a channel - you must include namespace name into channel name with : as a separator:
public:messages
gossips:messages
Where public and gossips are namespace names. Centrifugo looks for : symbol in the channel name, if found – extracts the namespace name, and applies namespace options while processing protocol commands from a client.
All things together here is an example of config.json which includes some top-level channel options set and has 2 additional channel namespaces configured:
{
"token_hmac_secret_key": "very-long-secret-key",
"api_key": "secret-api-key",
"presence": true,
"history_size": 10,
"history_ttl": "30s",
"namespaces": [
{
"name": "facts",
"history_size": 10,
"history_ttl": "300s"
},
{
"name": "gossips"
}
]
}
- Channel
newswill use globally defined channel options. - Channel
facts:sportwill usefactsnamespace options. - Channel
gossips:sportwill usegossipsnamespace options. - Channel
xxx:hellowill result into subscription error since there is noxxxnamespace defined in the configuration above.
Channel namespaces also work with private channels and user-limited channels. For example, if you have a namespace called dialogs then the private channel can be constructed as $dialogs:gossips, user-limited channel can be constructed as dialogs:dialog#1,2.
There is no inheritance in channel options and namespaces – for example, you defined presence: true on a top level of configuration and then defined a namespace – that namespace won't have online presence enabled - you must enable it for a namespace explicitly.
There are many options which can be set for channel namespace (on top-level and to named one) to modify behavior of channels belonging to a namespace. Below we describe all these options.
Channel options
Channel behavior can be modified by using channel options. Channel options can be defined on configuration top-level and for every namespace.
presence
presence (boolean, default false) – enable/disable online presence information for channels in a namespace.
Online presence is information about clients currently subscribed to the channel. It contains each subscriber's client ID, user ID, connection info, and channel info. By default, this option is off so no presence information will be available for channels.
Let's say you have a channel chat:index and 2 users (with ID 2694 and 56) subscribed to it. And user 2694 has 2 connections to Centrifugo in different browser tabs. In presence data you may see sth like this:
curl --header "Content-Type: application/json" \
--header "Authorization: apikey <API_KEY>" \
--request POST \
--data '{"method": "presence", "params": {"channel": "chat:index"}}' \
http://localhost:8000/api
{
"result": {
"presence": {
"66fdf8d1-06f0-4375-9fac-db959d6ee8d6": {
"user": "2694",
"client": "66fdf8d1-06f0-4375-9fac-db959d6ee8d6",
"conn_info": {"name": "Alex"}
},
"d4516dd3-0b6e-4cfe-84e8-0342fd2bb20c": {
"user": "2694",
"client": "d4516dd3-0b6e-4cfe-84e8-0342fd2bb20c",
"conn_info": {"name": "Alex"}
}
"g3216dd3-1b6e-tcfe-14e8-1342fd2bb20c": {
"user": "56",
"client": "g3216dd3-1b6e-tcfe-14e8-1342fd2bb20c",
"conn_info": {"name": "Alice"}
}
}
}
}
To call presence API from the client connection side client must have permission to do so. See presence permission model.
Enabling channel online presence adds some overhead since Centrifugo needs to maintain an additional data structure (in a process memory or in a broker memory/disk). So only use it for channels where presence is required.
See more details about online presence design.
join_leave
join_leave (boolean, default false) – enable/disable sending join and leave messages when the client subscribes to a channel (unsubscribes from a channel). Join/leave event includes information about the connection that triggered an event – client ID, user ID, connection info, and channel info (similar to entry inside presence information).
Enabling join_leave means that Join/Leave messages will start being emitted, but by default they are not delivered to clients subscribed to a channel. You need to force this using namespace option force_push_join_leave or explicitly provide intent from a client-side (in this case client must have permission to call presence API).
Keep in mind that join/leave messages can generate a huge number of messages in a system if turned on for channels with a large number of active subscribers. If you have channels with a large number of subscribers consider avoiding using this feature. It's hard to say what is "large" for you though – just estimate the load based on the fact that each subscribe/unsubscribe event in a channel with N subscribers will result into N messages broadcasted to all. If all clients reconnect at the same time the amount of generated messages is N^2.
Join/leave messages distributed only with at most once delivery guarantee.
force_push_join_leave
Boolean, default false.
When on all clients will receive join/leave events for a channel in a namespace automatically – without explicit intent to consume join/leave messages from the client side.
If pushing join/leave is not forced then client can provide a corresponding Subscription option to enable it – but it should have permissions to access channel presence (by having an explicit capability or if allowed on a namespace level).
history_size
history_size (integer, default 0) – history size (amount of messages) for channels. As Centrifugo keeps all history messages in process memory (or in a broker memory) it's very important to limit the maximum amount of messages in channel history with a reasonable value. history_size defines the maximum amount of messages that Centrifugo will keep for each channel in the namespace. As soon as history has more messages than defined by history size – old messages will be evicted.
Setting only history_size is not enough to enable history in channels – you also need to wisely configure history_ttl option (see below).
Enabling channel history adds some overhead (both memory and CPU) since Centrifugo needs to maintain an additional data structure (in a process memory or a broker memory/disk). So only use history for channels where it's required.
history_ttl
history_ttl (duration, default 0s) – interval how long to keep channel history messages (with seconds precision).
As all history is storing in process memory (or in a broker memory) it is also very important to get rid of old history data for unused (inactive for a long time) channels.
By default history TTL duration is zero – this means that channel history is disabled.
Again – to turn on history you should wisely configure both history_size and history_ttl options.
For example for top-level channels (which do not belong to a namespace):
{
...
"history_size": 10,
"history_ttl": "60s"
}
Let's look at example. You enabled history for a namespace chat and sent two messages in channel chat:index. Then history will contain sth like this:
curl --header "Content-Type: application/json" \
--header "Authorization: apikey <API_KEY>" \
--request POST \
--data '{"method": "history", "params": {"channel": "chat:index", "limit": 100}}' \
http://localhost:8000/api
{
"result": {
"publications": [
{
"data": {
"input": "1"
},
"offset": 1
},
{
"data": {
"input": "2"
},
"offset": 2
}
],
"epoch": "gWuY",
"offset": 2
}
}
To call history API from the client connection side client must have permission to do so. See history permission model.
See additional information about offsets and epoch in History and recovery chapter.
History persistence properties are dictated by Centrifugo engine used. For example, when using memory engine history is only kept till Centrifugo node restart. In Redis engine case persistence is determined by a Redis server persistence configuration (same for KeyDB and Tarantool).
force_positioning
force_positioning (boolean, default false) – when the force_positioning option is on Centrifugo forces all subscriptions in a namespace to be positioned. I.e. Centrifugo will try to compensate at most once delivery of PUB/SUB broker checking client position inside a stream.
If Centrifugo detects a bad position of the client (i.e. potential message loss) it disconnects a client with the Insufficient state disconnect code. Also, when the position option is enabled Centrifugo exposes the current stream top offset and current epoch in subscribe reply making it possible for a client to manually recover its state upon disconnect using history API.
force_positioning option must be used in conjunction with reasonably configured message history for a channel i.e. history_size and history_ttl must be set (because Centrifugo uses channel history to check client position in a stream).
If positioning is not forced then client can provide a corresponding Subscription option to enable it – but it should have permissions to access channel history (by having an explicit capability or if allowed on a namespace level).
force_recovery
force_recovery (boolean, default false) – when the position option is on Centrifugo forces all subscriptions in a namespace to be recoverable. When enabled Centrifugo will try to recover missed publications in channels after a client reconnects for some reason (bad internet connection for example). Also when the recovery feature is on Centrifugo automatically enables properties of the force_positioning option described above.
force_recovery option must be used in conjunction with reasonably configured message history for channel i.e. history_size and history_ttl must be set (because Centrifugo uses channel history to recover messages).
If recovery is not forced then client can provide a corresponding Subscription option to enable it – but it should have permissions to access channel history (by having an explicit capability or if allowed on a namespace level).
Not all real-time events require this feature turned on so think wisely when you need this. When this option is turned on your application should be designed in a way to tolerate duplicate messages coming from a channel (currently Centrifugo returns recovered publications in order and without duplicates but this is an implementation detail that can be theoretically changed in the future). See more details about how recovery works in special chapter.
allow_subscribe_for_client
allow_subscribe_for_client (boolean, default false) – when on all non-anonymous clients will be able to subscribe to any channel in a namespace. To additionally allow anonymous users to subscribe turn on allow_subscribe_for_anonymous (see below).
Turning this option on effectively makes namespace public – no subscribe permissions will be checked (only the check that current connection is authenticated - i.e. has non-empty user ID). Make sure this is really what you want in terms of channels security.
allow_subscribe_for_anonymous
allow_subscribe_for_anonymous (boolean, default false) – turn on if anonymous clients (with empty user ID) should be able to subscribe on channels in a namespace.
allow_publish_for_subscriber
allow_publish_for_subscriber (boolean, default false) - when the allow_publish_for_subscriber option is enabled client can publish into a channel in namespace directly from the client side over real-time connection but only if client subscribed to that channel.
Keep in mind that in this case subscriber can publish any payload to a channel – Centrifugo does not validate input at all. Your app backend won't receive those messages - publications just go through Centrifugo towards channel subscribers. Consider always validate messages which are being published to channels (i.e. using server API to publish after validating input on the backend side, or using publish proxy - see idiomatic usage).
allow_publish_for_subscriber (or allow_publish_for_client mentioned below) option still can be useful to send something without backend-side validation and saving it into a database – for example, this option may be handy for demos and quick prototyping real-time app ideas.
allow_publish_for_client
allow_publish_for_client (boolean, default false) – when on allows clients to publish messages into channels directly (from a client-side). It's like allow_publish_for_subscriber – but client should not be a channel subscriber to publish.
Keep in mind that in this case client can publish any payload to a channel – Centrifugo does not validate input at all. Your app backend won't receive those messages - publications just go through Centrifugo towards channel subscribers. Consider always validate messages which are being published to channels (i.e. using server API to publish after validating input on the backend side, or using publish proxy - see idiomatic usage).
allow_publish_for_anonymous
allow_publish_for_anonymous (boolean, default false) – turn on if anonymous clients should be able to publish into channels in a namespace.
allow_history_for_subscriber
allow_history_for_subscriber (boolean, default false) – allows clients who subscribed on a channel to call history API from that channel.
allow_history_for_client
allow_history_for_client (boolean, default false) – allows all clients to call history information in a namespace.
allow_history_for_anonymous
allow_history_for_anonymous (boolean, default false) – turn on if anonymous clients should be able to call history from channels in a namespace.
allow_presence_for_subscriber
allow_presence_for_subscriber (boolean, default false) – allows clients who subscribed on a channel to call presence information from that channel.
allow_presence_for_client
allow_presence_for_client (boolean, default false) – allows all clients to call presence information in a namespace.
allow_presence_for_anonymous
allow_presence_for_anonymous (boolean, default false) – turn on if anonymous clients should be able to call presence from channels in a namespace.
allow_user_limited_channels
allow_user_limited_channels (boolean, default false) - allows using user-limited channels in a namespace for checking subscribe permission.
If client subscribes to a user-limited channel while this option is off then server rejects subscription with 103: permission denied error.
channel_regex
channel_regex (string, default "") – is an option to set a regular expression for channels allowed in the namespace. By default Centrifugo does not limit channel name variations. For example, if you have a namespace chat, then channel names inside this namespace are not really limited, it can be chat:index, chat:1, chat:2, chat:zzz and so on. But if you want to be strict and know possible channel patterns you can use channel_regex option. This is especially useful in namespaces where all clients can subscribe to channels.
For example, let's only allow digits after chat: for channel names in a chat namespace:
{
"namespaces": [
{
"name": "chat",
"allow_subscribe_for_client": true,
"channel_regex": "^[\d+]$"
}
]
}
Note, that we are skipping chat: part in regex. Since namespace prefix is the same for all channels in a namespace we only match the rest (after the prefix) of channel name.
Channel regex only checked for client-side subscriptions, if you are using server-side subscriptions Centrifugo won't check the regex.
Centrifugo uses Go language regexp package for regular expressions.
proxy_subscribe
proxy_subscribe (boolean, default false) – turns on subscribe proxy, more info in proxy chapter
proxy_publish
proxy_publish (boolean, default false) – turns on publish proxy, more info in proxy chapter
proxy_sub_refresh
proxy_sub_refresh (boolean, default false) – turns on sub refresh proxy, more info in proxy chapter
subscribe_proxy_name
subscribe_proxy_name (string, default "") – turns on subscribe proxy when granular proxy mode is used. Note that proxy_subscribe option defined above is ignored in granular proxy mode.
publish_proxy_name
publish_proxy_name (string, default "") – turns on publish proxy when granular proxy mode is used. Note that proxy_publish option defined above is ignored in granular proxy mode.
sub_refresh_proxy_name
sub_refresh_proxy_name (string, default "") – turns on sub refresh proxy when granular proxy mode is used. Note that proxy_sub_refresh option defined above is ignored in granular proxy mode.
Channel config examples
Let's look at how to set some of these options in a config. In this example we turning on presence, history features, forcing publication recovery. Also allowing all client connections (including anonymous users) to subscribe to channels and call publish, history, presence APIs if subscribed.
{
"token_hmac_secret_key": "my-secret-key",
"api_key": "secret-api-key",
"presence": true,
"history_size": 10,
"history_ttl": "300s",
"force_recovery": true,
"allow_subscribe_for_client": true,
"allow_subscribe_for_anonymous": true,
"allow_publish_for_subscriber": true,
"allow_publish_for_anonymous": true,
"allow_history_for_subscriber": true,
"allow_history_for_anonymous": true,
"allow_presence_for_subscriber": true,
"allow_presence_for_anonymous": true
}
Here we set channel options on config top-level – these options will affect channels without namespace. In many cases defining namespaces is a recommended approach so you can manage options for every real-time feature separately. With namespaces the above config may transform to:
{
"token_hmac_secret_key": "my-secret-key",
"api_key": "secret-api-key",
"namespaces": [
{
"name": "feed",
"presence": true,
"history_size": 10,
"history_ttl": "300s",
"force_recovery": true,
"allow_subscribe_for_client": true,
"allow_subscribe_for_anonymous": true,
"allow_publish_for_subscriber": true,
"allow_publish_for_anonymous": true,
"allow_history_for_subscriber": true,
"allow_history_for_anonymous": true,
"allow_presence_for_subscriber": true,
"allow_presence_for_anonymous": true
}
]
}
In this case channels should be prefixed with feed: to follow the behavior configured for a feed namespace.