Improving Centrifugo Redis Engine throughput and allocation efficiency with Rueidis Go library
In this post we share some details about Centrifugo Redis Engine implementation and its recent performance improvements with the help of Rueidis Go library
The main objective of Centrifugo is to manage persistent client connections established over various real-time transports (including WebSocket, HTTP-Streaming, SSE, WebTransport, etc – see here) and offer an API for publishing data towards established connections. Clients subscribe to channels, hence Centrifugo implements PUB/SUB mechanics to transmit published data to all online channel subscribers.
Centrifugo employs Redis as its primary scalability option – so that it's possible to distribute client connections amongst numerous Centrifugo nodes without worrying about channel subscribers connected to separate nodes. Redis is incredibly mature, simple, and fast in-memory storage. Due to various built-in data structures and PUB/SUB support Redis is a perfect fit to be both Centrifugo Broker and PresenceManager (we will describe what's this shortly).
In Centrifugo v4.1.0 we introduced an updated implementation of our Redis Engine (Engine in Centrifugo == Broker + PresenceManager) which provides sufficient performance improvements to our users. This post discusses the factors that prompted us to update Redis Engine implementation and provides some insight into the results we managed to achieve. We'll examine a few well-known Go libraries for Redis communication and contrast them against Centrifugo tasks.
Broker and PresenceManager
Before we get started, let's define what Centrifugo's Broker and PresenceManager terms mean.
Broker is an interface responsible for maintaining subscriptions from different Centrifugo nodes (initiated by client connections). That helps to scale client connections over many Centrifugo instances and not worry about the same channel subscribers being connected to different nodes – since all Centrifugo nodes connected with PUB/SUB. Messages published to one node are delivered to a channel subscriber connected to another node.
Another major part of Broker is keeping an expiring publication history for channels (streams). So that Centrifugo may provide a fast cache for messages missed by clients upon going offline for a short period and compensate at most once delivery of Redis PUB/SUB using Publication incremental offsets. Centrifugo uses STREAM and HASH data structures in Redis to store channel history and stream meta information.
In general Centrifugo architecture may be perfectly illustrated by this picture (Gophers are Centrifugo nodes all connected to Broker, and sockets are WebSockets):
PresenceManager is an interface responsible for managing online presence information - list of currently active channel subscribers. While the connection is alive we periodically update presence entries for channels connection subscribed to (for channels where presence is enabled). Presence data should expire if not updated by a client connection for some time. Centrifugo uses two Redis data structures for managing presence in channels - HASH and ZSET.
Redigo
For a long time, the gomodule/redigo package served as the foundation for the Redis Engine implementation in Centrifugo. Huge props go to Mr Gary Burd for creating it.
Redigo offers a connection Pool to Redis. A simple usage of it involves getting the connection from the pool, issuing request to Redis over that connection, and then putting the connection back to the pool after receiving the result from Redis.
Let's write a simple benchmark which demonstrates simple usage of Redigo and measures SET operation performance:
func BenchmarkRedigo(b *testing.B) {
pool := redigo.Pool{
MaxIdle: 128,
MaxActive: 128,
Wait: true,
Dial: func() (redigo.Conn, error) {
return redigo.Dial("tcp", ":6379")
},
}
defer pool.Close()
b.ResetTimer()
b.SetParallelism(128)
b.ReportAllocs()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
c := pool.Get()
_, err := c.Do("SET", "redigo", "test")
if err != nil {
b.Fatal(err)
}
c.Close()
}
})
}
Let's run it:
BenchmarkRedigo-8 228804 4648 ns/op 62 B/op 2 allocs/op
Seems pretty fast, but we can improve it further.
Redigo with pipelining
To increase a throughput in Centrifugo, instead of using Redigo's Pool for each operation, we acquired a dedicated connection from the Pool and utilized Redis pipelining to send multiple commands where possible.
Redis pipelining improves performance by executing multiple commands using a single client-server-client round trip. Instead of executing many commands one by one, you can queue the commands in a pipeline and then execute the queued commands as if it is a single command. Redis processes commands in order and sends individual response for each command. Given a single CPU nature of Redis, reducing the number of active connections when using pipelining has a positive impact on throughput – therefore pipelining is beneficial from this angle as well.
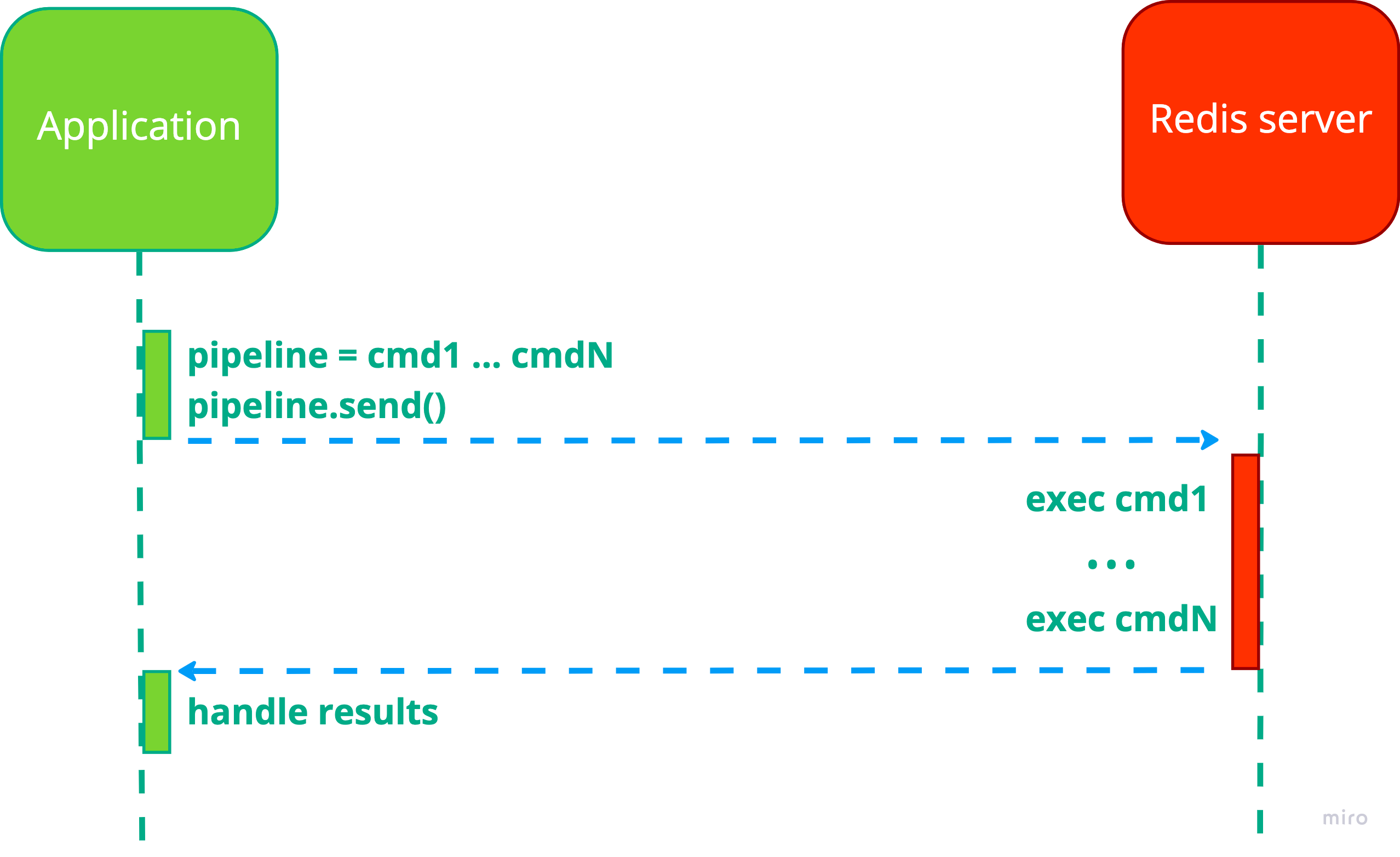
You can quickly estimate the benefits of pipelining by running Redis locally and running redis-benchmark which comes with Redis distribution over it:
> redis-benchmark -n 100000 set key value
Summary:
throughput summary: 84674.01 requests per second
And with pipelining:
> redis-benchmark -n 100000 -P 64 set key value
Summary:
throughput summary: 666880.00 requests per second
In Centrifugo we are using smart batching technique for collecting pipeline (also described in one of the previous posts in this blog).
To demonstrate benefits from using pipelining let's look at the following benchmark:
const (
maxCommandsInPipeline = 512
numPipelineWorkers = 1
)
type command struct {
errCh chan error
}
type sender struct {
cmdCh chan command
pool redigo.Pool
}
func newSender(pool redigo.Pool) *sender {
p := &sender{
cmdCh: make(chan command),
pool: pool,
}
go func() {
for {
for i := 0; i < numPipelineWorkers; i++ {
p.runPipelineRoutine()
}
}
}()
return p
}
func (s *sender) send() error {
errCh := make(chan error, 1)
cmd := command{
errCh: errCh,
}
// Submit command to be executed by runPipelineRoutine.
s.cmdCh <- cmd
return <-errCh
}
func (s *sender) runPipelineRoutine() {
conn := p.pool.Get()
defer conn.Close()
for {
select {
case cmd := <-s.cmdCh:
commands := []command{cmd}
conn.Send("set", "redigo", "test")
loop:
// Collect batch of commands to send to Redis in one RTT.
for i := 0; i < maxCommandsInPipeline; i++ {
select {
case cmd := <-s.cmdCh:
commands = append(commands, cmd)
conn.Send("set", "redigo", "test")
default:
break loop
}
}
// Flush all collected commands to the network.
err := conn.Flush()
if err != nil {
for i := 0; i < len(commands); i++ {
commands[i].errCh <- err
}
continue
}
// Read responses to commands, they come in order.
for i := 0; i < len(commands); i++ {
_, err := conn.Receive()
commands[i].errCh <- err
}
}
}
}
func BenchmarkRedigoPipelininig(b *testing.B) {
pool := redigo.Pool{
Wait: true,
Dial: func() (redigo.Conn, error) {
return redigo.Dial("tcp", ":6379")
},
}
defer pool.Close()
sender := newSender(pool)
b.ResetTimer()
b.SetParallelism(128)
b.ReportAllocs()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
err := sender.send()
if err != nil {
b.Fatal(err)
}
}
})
}
This is a strategy that we employed in Centrifugo for a long time. As you can see code with automatic pipelining gets more complex, and in real life it's even more complicated to support different types of commands, channel send timeouts, and server shutdowns.
What about the performance of this approach?
BenchmarkRedigo-8 228804 4648 ns/op 62 B/op 2 allocs/op
BenchmarkRedigoPipelininig-8 1840758 604.7 ns/op 176 B/op 4 allocs/op
Operation latency reduced from 4648 ns/op to 604.7 ns/op – not bad right?
It's worth mentioning that upon increased RTT between application and Redis the approach with pipelining will provide worse throughput. But it still can be better than in pool-based approach. Let's say we have latency 5ms between app and Redis. This means that with pool size of 128 you will be able to issue up to 128 * (1000 / 5) = 25600 requests per second over 128 connections. With the pipelining approach above the theoretical limit is 512 * (1000 / 5) = 102400 requests per second over a single connection (though in case of using code for pipelining shown above we need to have larger parallelism, say 512 instead of 128). And it can scale further if you increase numPipelineWorkers to work over several connections in paralell. Though increasing numPipelineWorkers has negative effect on CPU – we will discuss this later in this post.
Redigo is an awesome battle-tested library that served us great for a long time.
Motivation to migrate
There are three modes in which Centrifugo can work with Redis these days:
- Connecting to a standalone single Redis instance
- Connecting to Redis in master-replica configuration, where Redis Sentinel controls the failover process
- Connecting to Redis Cluster
All modes additionally can be used with client-side consistent sharding. So it's possible to scale Redis even without a Redis Cluster setup.
Unfortunately, with pure Redigo library, it's only possible to implement [ 1 ] – i.e. connecting to a single standalone Redis instance.
To support the scheme with Sentinel you whether need to have a proxy between the application and Redis which proxies the connection to Redis master. For example, with Haproxy it's possible in this way:
listen redis
server redis-01 127.0.0.1:6380 check port 6380 check inter 2s weight 1 inter 2s downinter 5s rise 10 fall 2 on-marked-down shutdown-sessions on-marked-up shutdown-backup-sessions
server redis-02 127.0.0.1:6381 check port 6381 check inter 2s weight 1 inter 2s downinter 5s rise 10 fall 2 backup
bind *:6379
mode tcp
option tcpka
option tcplog
option tcp-check
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
balance roundrobin
Or, you need to additionally import FZambia/sentinel library - which provides a communication layer with Redis Sentinel on top of Redigo's connection Pool.
For communicating with Redis Cluster one more library may be used – mna/redisc which is also a layer on top of redigo basic functionality.
Combining redigo + FZambia/sentinel + mna/redisc we managed to implement all three connection modes. This worked, though resulted in rather tricky Redis setup. Also, it was difficult to re-use existing pipelining code we had for a standalone Redis with Redis Cluster. As a result, Centrifugo only used pipelining in a standalone or Sentinel Redis cases. When using Redis Cluster, however, Centrifugo merely used the connection pool to issue requests thus not benefiting from request pipelining. Due to this we had some code duplication to send the same requests in various Redis configurations.
Another thing is that Redigo uses interface{} for command construction. To send command to Redis Redigo has Do method which accepts name of the command and variadic interface{} arguments to construct command arguments:
Do(commandName string, args ...interface{}) (reply interface{}, err error)
While this works well and you can issue any command to Redis, you need to be very accurate when constructing a command. This also adds some allocation overhead. As we know more memory allocations lead to the increased CPU utilization because the allocation process itself requires more processing power and the GC is under more strain.
At some point we felt that eliminating additional dependencies (even though I am the author of one of them) and reducing allocations in Redis communication layer is a nice step forward for Centrifugo. So we started looking around for redigo alternatives.
To summarize, here is what we wanted from Redis library:
- Possibility to work with all three Redis setup options we support: standalone, master-replica(s) with Sentinel, Redis Cluster, so we can depend on one library instead of three
- Less memory allocations (and more type-safety API is a plus)
- Support working with RESP2-only Redis servers as we need that for backwards compatibility. And some vendors like Redis Enterprise still support RESP2 protocol only
- The library should be actively maintained
Go-redis/redis
The most obvious alternative to Redigo is go-redis/redis package. It's popular, regularly gets updates, used by a huge amount of Go projects (Grafana, Thanos, etc.). And maintained by
Vladimir Mihailenco who created several more awesome Go libraries, like msgpack for example. I personally successfully used go-redis/redis in several other projects I worked on.
To avoid setup boilerplate for various Redis installation variations go-redis/redis has UniversalClient. From docs:
UniversalClient is a wrapper client which, based on the provided options, represents either a ClusterClient, a FailoverClient, or a single-node Client. This can be useful for testing cluster-specific applications locally or having different clients in different environments.
In terms of implementation go-redis/redis also has internal pool of connections to Redis, similar to redigo. It's also possible to use Client.Pipeline method to allocate a Pipeliner interface and use it for pipelining. So UniversalClient reduces setup boilerplate for different Redis installation types and number of dependencies we had, and it provide very similar way to pipeline requests so we could easily re-implement things we had with Redigo.
Go-redis also provides more type-safety when constructing commands compared to Redigo, almost every command in Redis is implemented as a separate method of Client, for example Publish defined as:
func (c Client) Publish(ctx context.Context, channel string, message interface{}) *IntCmd
You can see though that we still have interface{} here for message argument type. I suppose this was implemented in such way for convenience – to pass both string or []byte. But it still produces some extra allocations.
Without pipelining the simplest program with go-redis/redis may look like this:
func BenchmarkGoredis(b *testing.B) {
client := redis.NewUniversalClient(&redis.UniversalOptions{
Addrs: []string{":6379"},
PoolSize: 128,
})
defer client.Close()
b.ResetTimer()
b.SetParallelism(128)
b.ReportAllocs()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
resp := client.Set(context.Background(), "goredis", "test", 0)
if resp.Err() != nil {
b.Fatal(resp.Err())
}
}
})
}
Let's run it:
BenchmarkRedigo-8 228804 4648 ns/op 62 B/op 2 allocs/op
BenchmarkGoredis-8 268444 4561 ns/op 244 B/op 8 allocs/op
Result is pretty comparable to Redigo, though Go-redis allocates more (btw most of allocations come from the connection liveness check upon getting from the pool which can not be turned off).
It's interesting – if we dive deeper into what is it we can discover that this is the only way in Go to check connection was closed without reading data from it. The approach was originally introduced by go-sql-driver/mysql, it's not cross-platform, and related issue may be found in Go issue tracker.
But as I said in Centrifugo we already used pipelining over the dedicated connection for all operations so we avoid frequently getting connections from the pool. And early experiments proved that go-redis may provide some performance benefits for our use case.
At some point @j178 sent a pull request to Centrifuge library with Broker and PresenceManager implementations based on go-redis/redis. The amount of code to cover all the various Redis setups was reduced, we got only one dependency instead of three 🔥
But what about performance? Here we will show results for several operations which are typical for Centrifugo:
- Publish a message to a channel without saving it to the history - this is just a Redis PUBLISH command going through Redis PUB/SUB system (
RedisPublish) - Publish message to a channel with saving it to history - this involves executing the LUA script on Redis side where we add a publication to STREAM data structure, update meta information HASH, and finally PUBLISH to PUB/SUB (
RedisPublish_History) - Subscribe to a channel - that's a SUBSCRIBE Redis command, this is important to have it fast as Centrifugo should be able to re-subscribe to all the channels in the system upon mass client reconnect scenario (
RedisSubscribe) - Recovering missed publication state from channel STREAM, this is again may be called lots of times when all clients reconnect at once (
RedisRecover). - Updating connection presence information - many connections may periodically update their channel online presence information in Redis (
RedisAddPresence)
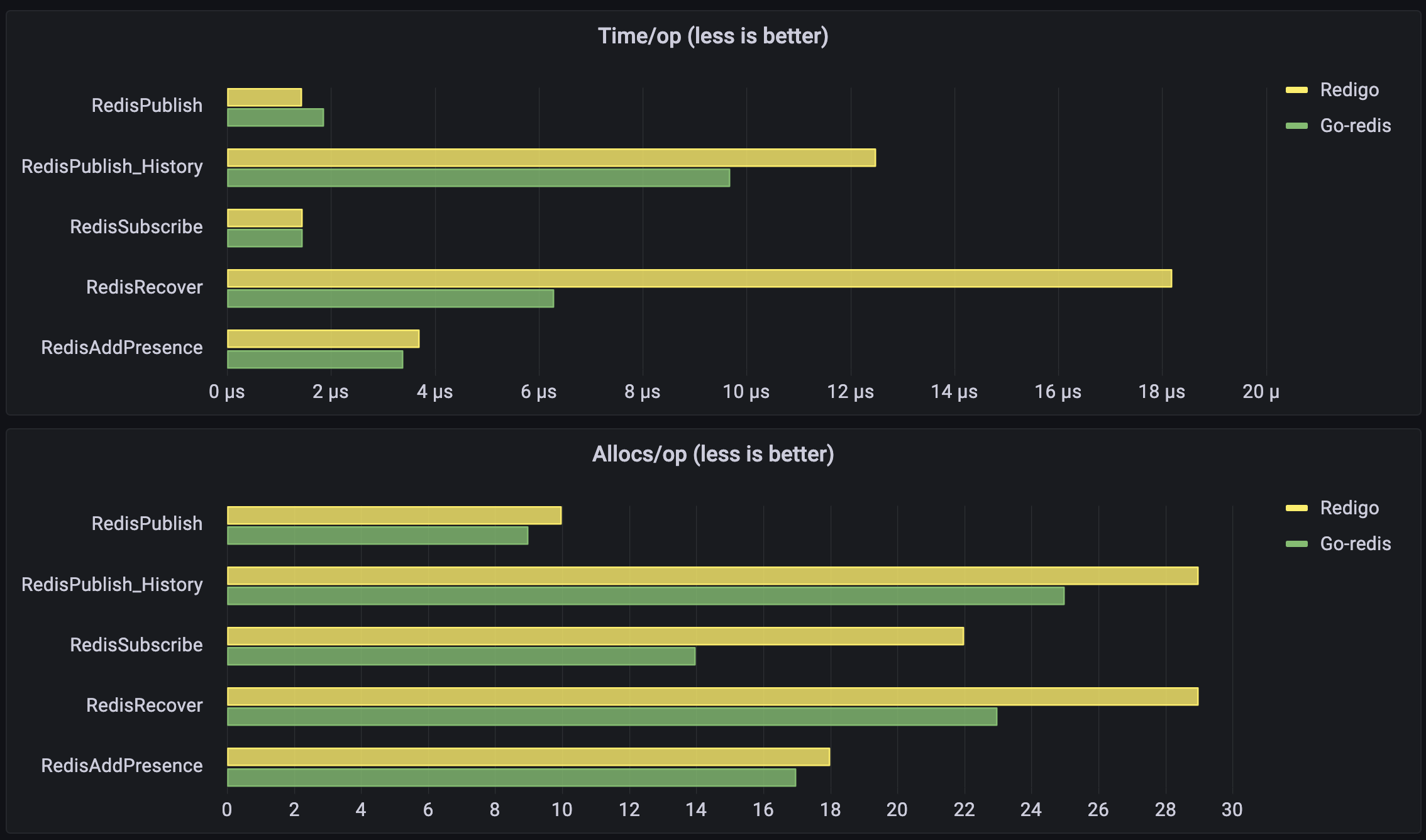
Here are the benchmark results we got when comparing redigo (v1.8.9) implementation (old) and go-redis/redis (v9.0.0-rc.2) implementation (new) with Redis v6.2.7 on Mac with M1 processor and benchmark paralellism 128:
❯ benchstat redigo_p128.txt goredis_p128.txt
name old time/op new time/op delta
RedisPublish-8 1.45µs ±10% 1.88µs ± 4% +29.32% (p=0.000 n=10+10)
RedisPublish_History-8 12.5µs ± 6% 9.7µs ± 3% -22.77% (p=0.000 n=10+10)
RedisSubscribe-8 1.47µs ±24% 1.47µs ±10% ~ (p=0.469 n=10+10)
RedisRecover-8 18.4µs ± 2% 6.3µs ± 0% -65.78% (p=0.000 n=10+8)
RedisAddPresence-8 3.72µs ± 1% 3.40µs ± 1% -8.74% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
RedisPublish-8 483B ± 0% 499B ± 0% +3.37% (p=0.000 n=9+10)
RedisPublish_History-8 1.30kB ± 0% 1.08kB ± 0% -16.67% (p=0.000 n=10+10)
RedisSubscribe-8 892B ± 2% 662B ± 6% -25.83% (p=0.000 n=10+10)
RedisRecover-8 1.25kB ± 1% 1.00kB ± 0% -19.91% (p=0.000 n=10+10)
RedisAddPresence-8 907B ± 0% 827B ± 0% -8.82% (p=0.002 n=7+8)
name old allocs/op new allocs/op delta
RedisPublish-8 10.0 ± 0% 9.0 ± 0% -10.00% (p=0.000 n=10+10)
RedisPublish_History-8 29.0 ± 0% 25.0 ± 0% -13.79% (p=0.000 n=10+10)
RedisSubscribe-8 22.0 ± 0% 14.0 ± 0% -36.36% (p=0.000 n=8+7)
RedisRecover-8 29.0 ± 0% 23.0 ± 0% -20.69% (p=0.000 n=10+10)
RedisAddPresence-8 18.0 ± 0% 17.0 ± 0% -5.56% (p=0.000 n=10+10)
Please note that this benchmark is not a pure performance comparison of two Go libraries for Redis – it's a performance comparison of Centrifugo Engine methods upon switching to a new library.
Or visualized in Grafana:
Centrifugo benchmarks results shown in the post use parallelism 128. If someone interested to check numbers for paralellism 1 or 16 – check out this comment on Github.
We observe a noticeable reduction in allocations in these benchmarks and in most benchmarks (presented here and other not listed in this post) we observed a reduced latency.
Overall, results convinced us that the migration from redigo to go-redis/redis may provide Centrifugo with everything we aimed for – all the goals for a redigo alternative outlined above were successfully fullfilled.
One good thing go-redis/redis allowed us to do is to use Redis pipelining also in a Redis Cluster case. It's possible due to the fact that go-redis/redis re-maps pipeline objects internally based on keys to execute pipeline on the correct node of Redis Cluster. Actually, we could do the same based on redigo + mna/redisc, but here we got it for free.
BTW, there is a page with comparison between redigo and go-redis/redis in go-redis/redis docs which outlines some things I mentioned here and some others.
But we have not migrated to go-redis/redis in the end. And the reason is another library – rueidis.
Rueidis
While results were good with go-redis/redis we also made an attempt to implement Redis Engine on top of rueian/rueidis library written by @rueian. According to docs, rueidis is:
A fast Golang Redis client that supports Client Side Caching, Auto Pipelining, Generics OM, RedisJSON, RedisBloom, RediSearch, RedisAI, RedisGears, etc.
The readme of rueidis contains benchmark results where it hugely outperforms go-redis/redis in terms of operation latency/throughput in both single Redis and Redis Custer setups:
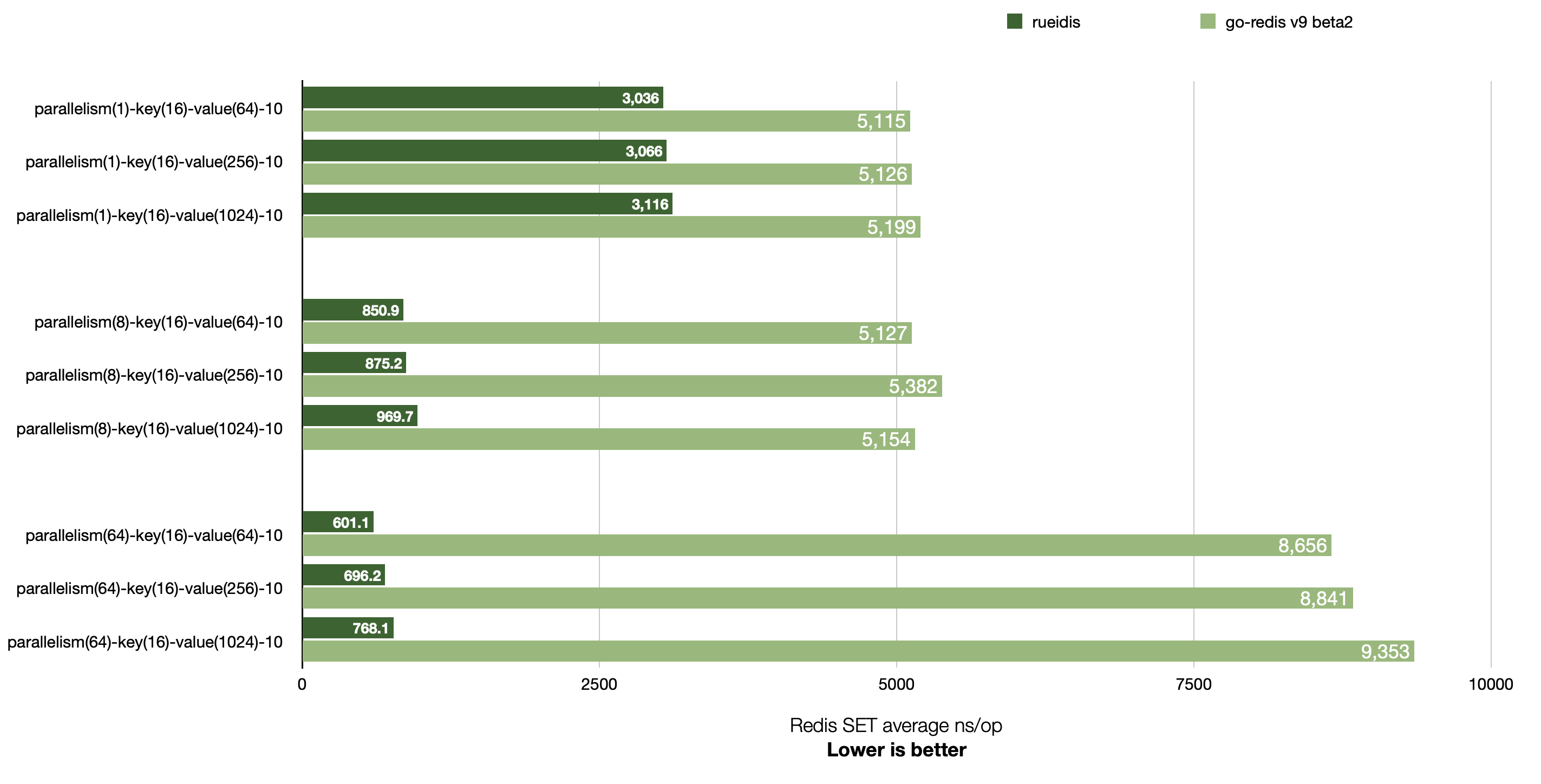
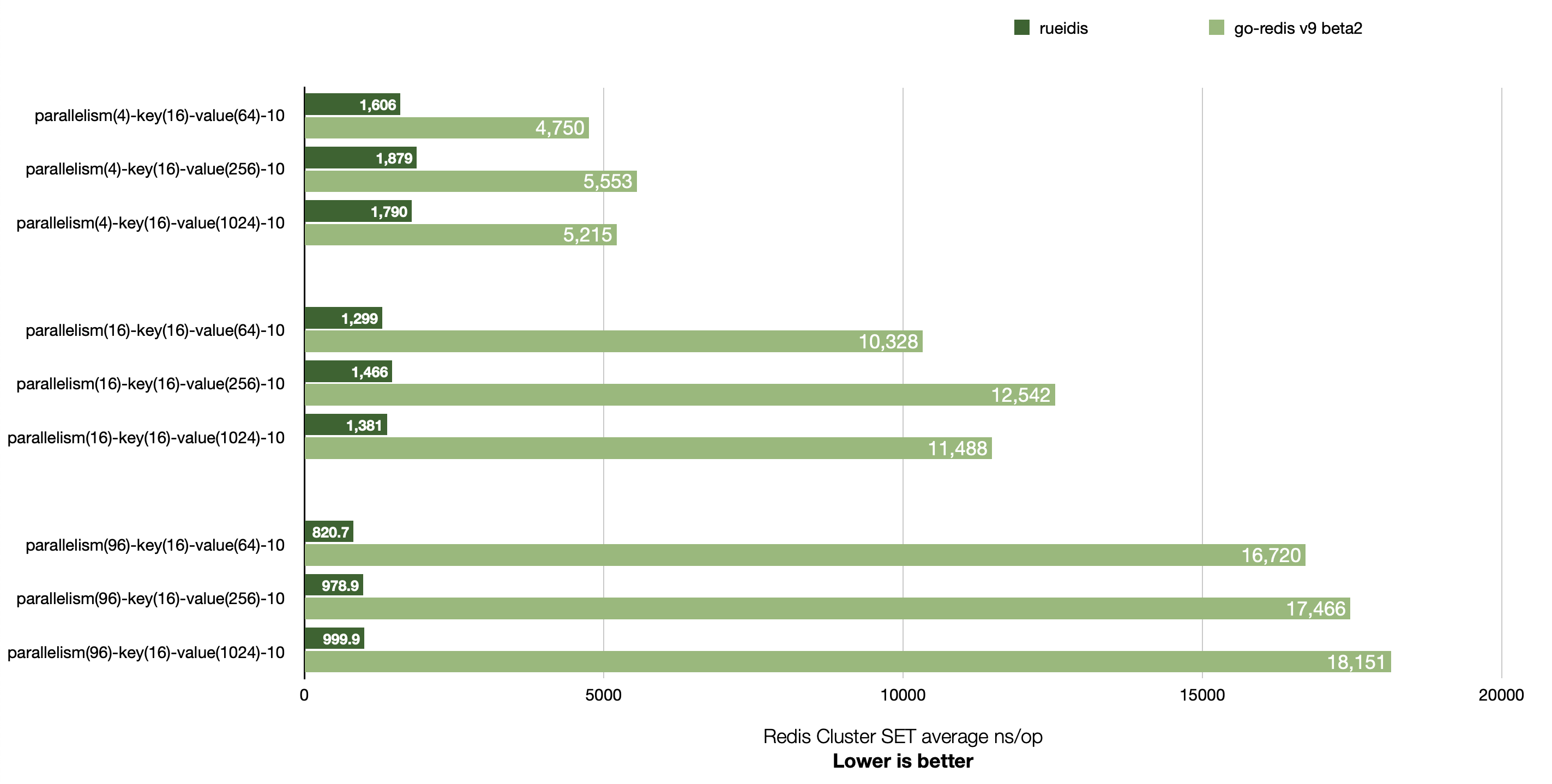
rueidis works with standalone Redis, Sentinel Redis and Redis Cluster out of the box. Just like UniversalClient of go-redis/redis. So it also allowed us to reduce code boilerplate to work with all these setups.
Again, let's try to write a simple program like we had for Redigo and Go-redis above:
func BenchmarkRueidis(b *testing.B) {
client, err := rueidis.NewClient(rueidis.ClientOption{
InitAddress: []string{":6379"},
})
if err != nil {
b.Fatal(err)
}
b.ResetTimer()
b.SetParallelism(128)
b.ReportAllocs()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
cmd := client.B().Set().Key("rueidis").Value("test").Build()
res := client.Do(context.Background(), cmd)
if res.Error() != nil {
b.Fatal(res.Error())
}
}
})
}
And run it:
BenchmarkRedigo-8 228804 4648 ns/op 62 B/op 2 allocs/op
BenchmarkGoredis-8 268444 4561 ns/op 244 B/op 8 allocs/op
BenchmarkRueidis-8 2908591 418.5 ns/op 4 B/op 1 allocs/op
rueidis library comes with automatic implicit pipelining, so you can send each request in isolated way while rueidis makes sure the request becomes part of the pipeline sent to Redis – thus utilizing the connection between an application and Redis most efficiently with maximized throughput. The idea of implicit pipelining with Redis is not new and Go ecosystem already had joomcode/redispipe library which implemented it (though it comes with some limitations which made it unsuitable for Centrifugo use case).
So applications that use a pool-based approach for communication with Redis may observe dramatic improvements in latency and throughput when switching to the Rueidis library.
For Centrifugo we didn't expect such a huge speed-up as shown in the above graphs since we already used pipelining in Redis Engine. But rueidis implements some ideas which allow it to be efficient. Insights about these ideas are provided by Rueidis author in a "Writing a High-Performance Golang Client Library" series of posts on Medium:
- Part 1: Batching on Pipeline
- Part 2: Reading Again From Channels?
- Part 3: Remove the Bad Busy Loops With the Sync.Cond
I did some prototypes with rueidis which were super-promising in terms of performance. There were some issues found during that early prototyping (mostly with PUB/SUB) – but all of them were quickly resolved by Rueian.
Until v0.0.80 release rueidis did not support RESP2 though, so we could not replace our Redis Engine implementation with it. But as soon as it got RESP2 support we opened a pull request with alternative implementation.
Since auto-pipelining is used in rueidis by default we were able to remove some of our own pipelining management code – so the Engine implementation is more concise now. One more thing to mention is a simpler PUB/SUB code we were able to write with rueidis. One example is that in redigo case we had to periodically PING PUB/SUB connection to maintain it alive, rueidis does this automatically.
Regarding performance, here are the benchmark results we got when comparing redigo (v1.8.9) implementation (old) and rueidis (v0.0.90) implementation (new):
❯ benchstat redigo_p128.txt rueidis_p128.txt
name old time/op new time/op delta
RedisPublish-8 1.45µs ±10% 0.56µs ± 1% -61.53% (p=0.000 n=10+9)
RedisPublish_History-8 12.5µs ± 6% 9.7µs ± 1% -22.43% (p=0.000 n=10+9)
RedisSubscribe-8 1.47µs ±24% 1.45µs ± 1% ~ (p=0.484 n=10+9)
RedisRecover-8 18.4µs ± 2% 6.2µs ± 1% -66.08% (p=0.000 n=10+10)
RedisAddPresence-8 3.72µs ± 1% 3.60µs ± 1% -3.34% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
RedisPublish-8 483B ± 0% 91B ± 0% -81.16% (p=0.000 n=9+10)
RedisPublish_History-8 1.30kB ± 0% 0.39kB ± 0% -70.08% (p=0.000 n=10+8)
RedisSubscribe-8 892B ± 2% 360B ± 0% -59.66% (p=0.000 n=10+10)
RedisRecover-8 1.25kB ± 1% 0.36kB ± 1% -71.52% (p=0.000 n=10+10)
RedisAddPresence-8 907B ± 0% 151B ± 1% -83.34% (p=0.000 n=7+9)
name old allocs/op new allocs/op delta
RedisPublish-8 10.0 ± 0% 2.0 ± 0% -80.00% (p=0.000 n=10+10)
RedisPublish_History-8 29.0 ± 0% 10.0 ± 0% -65.52% (p=0.000 n=10+10)
RedisSubscribe-8 22.0 ± 0% 6.0 ± 0% -72.73% (p=0.002 n=8+10)
RedisRecover-8 29.0 ± 0% 7.0 ± 0% -75.86% (p=0.000 n=10+10)
RedisAddPresence-8 18.0 ± 0% 3.0 ± 0% -83.33% (p=0.000 n=10+10)
Or visualized in Grafana:
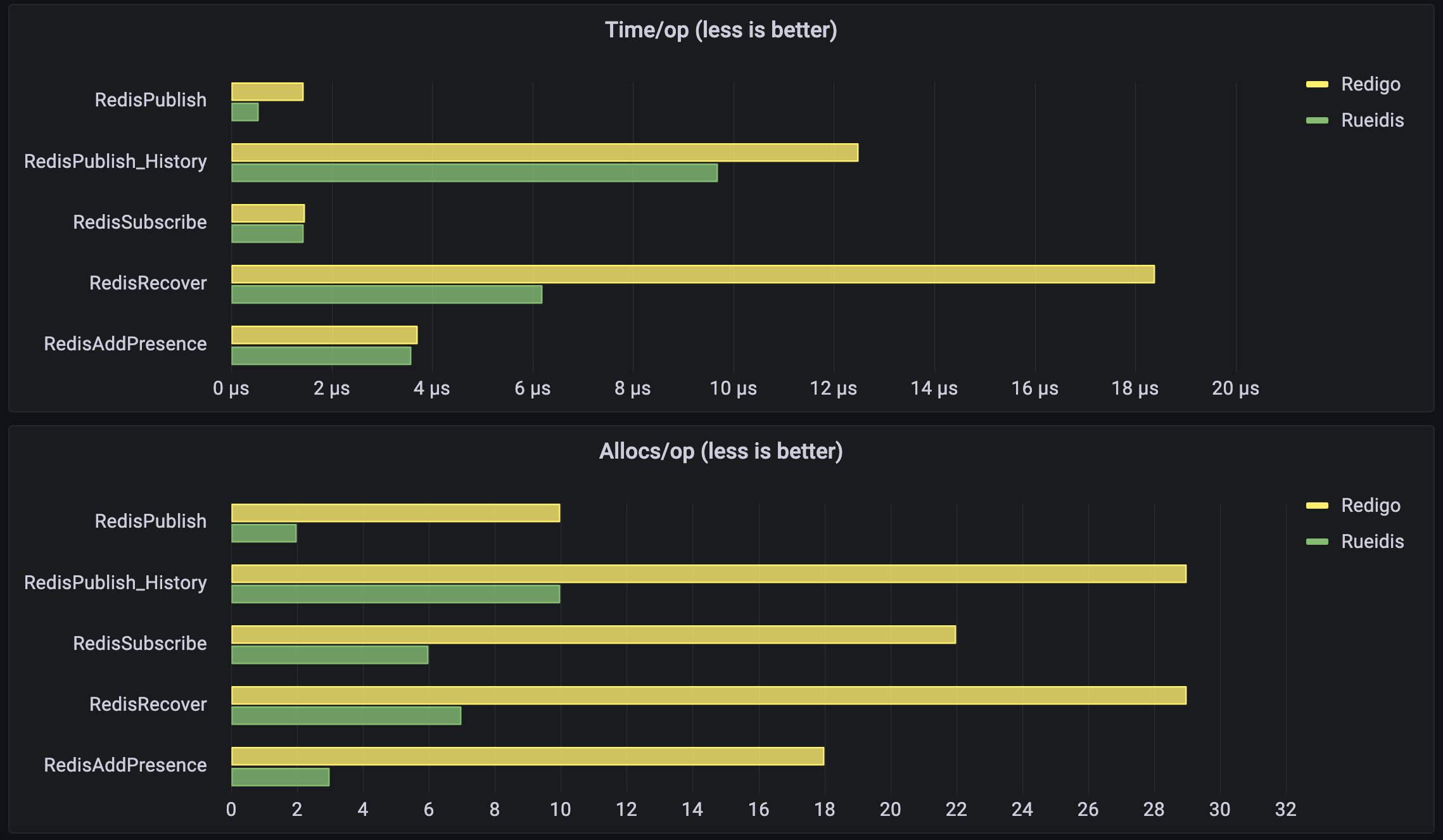
2.5x times more publication throughput than we had before! Instead of 700k publications/sec, we went towards 1.7 million publications/sec due to drastically decreased publish operation latency (1.45µs -> 0.59µs). This means that our previous Engine implementation under-utilized Redis, and Rueidis just pushes us towards Redis limits. The latency of most other operations is also reduced.
The allocation effectiveness of the implementation based on "rueidis" is best. As you can see rueidis helped us to generate sufficiently fewer memory allocations for all our Redis operations. Allocation improvements directly affect Centrifugo node CPU usage. Though we will talk about CPU more later below.
For Redis Cluster case we also got benchmark results similar to the standalone Redis results above.
I might add that I enjoyed building commands with rueidis. All Redis commands may be constructed using a builder approach. Rueidis comes with builders generated for all Redis commands. As an illustration, this is a process of building a PUBLISH Redis command:
This drastically reduces a chance to make a stupid mistake while constructing a command. Instead of always opening Redis docs to see a command syntax it's now possible to just start typing - and quickly come to the complete command to send.
Switching to Rueidis: reducing CPU usage
After making all these benchmarks and implementing Engine in Rueidis I decided to check whether Centrifugo consumes less CPU with it. I expected a notable CPU reduction as Rueidis Engine implementation allocates much less than Redigo-based. Turned out it's not that simple.
I ran Centrifugo with some artificial load and noticed that CPU consumption of the new implementation is actually... worse than we had with Redigo-based engine under equal conditions!😩 But why?
As I mentioned above Redis pipelining is a technique when several commands may be combined into one batch to send over the network. In case of automatic pipelining the size of generated batches start playing a crucial role in application and Redis CPU usage – since smaller command batches result into more read/write system calls to the kernel on both application and Redis server sides. That's why projects like Twemproxy which sit between app and Redis have sich a good effect on Redis CPU usage among other things.
As we have seen above, Rueidis provides a better throughput and latency, but it's more agressive in terms of flushing data to the network. So in its default configuration we get smaller batches under th equal conditions than we had before in our own pipelining implementation based on Redigo (shown in the beginning of this post).
Luckily, there is an option in Rueidis called MaxFlushDelay which allows to slow down write loop a bit to give Rueidis a chance to collect more commands to send in one batch. When this option is used Rueidis will make a pause after each network flush not bigger than selected value of MaxFlushDelay (please note, that this is a delay after flushing collected pipeline commands, not an additional delay for each request). Using some reasonable value it's possible to drastically reduce both application and Redis CPU utilization.
To demonstrate this I created a repo: https://github.com/FZambia/pipelines.
This repo contains three benchmarks where we use automatic pipelining: based on redigo, based on go-redis/redis and rueidis. In these benchmarks we produce concurrent requests, but instead of pushing the system towards the limits we are limiting number of requests sent to Redis, so we put all libraries in equal conditions.
To rate limit requests we are using uber-go/ratelimit library. For example, to allow rate no more than 100k commands per second we can do sth like this:
rl := ratelimit.New(100, ratelimit.Per(time.Millisecond))
for {
rl.Take()
...
}
We limit requests per second we could actually just write ratelimit.New(100000) – but we aim to get a more smooth distribution of requests over time - so using millisecond resolution.
Let's run all the benchmarks in the default configuration:
Average CPU usage during the test (a bit rough but enough for demonstration):
| Redigo | Go-redis/redis | Rueidis | |
|---|---|---|---|
| Application CPU, % | 95 | 99 | 116 |
| Redis CPU, % | 36 | 35 | 42 |
OK, Rueidis-based implementation is the worst here despite of allocating less than others. So let's try to change this by setting MaxFlushDelay to sth like 100 microseconds:
Now CPU usage is:
| Redigo | Go-redis/redis | Rueidis | |
|---|---|---|---|
| Application CPU, % | 95 | 99 | 59 |
| Redis CPU, % | 36 | 35 | 12 |
So we can achieve great CPU usage reduction. CPU went from 116% to 59% for the application side, and from 42% to only 12% for Redis! We are sacrificing latency though. Given the fact the CPU utilization reduction is very notable the trade-off is pretty fair.
It's definitely possible to improve CPU usage in Redigo and Go-redis/redis cases too – using similar technique. But the goal here was to improve Rueidis-based engine implementation to make it comparable or better than our Redigo-based implementation in terms of CPU utilization.
As you can see we were able to achieve better CPU results just by using 100 microseconds delay after each network flush. In real life, where we are not running Redis on localhost and have some network latency in between application and Redis, this delay should be insignificant at all. Indeed, adding MaxFlushDelay can even improve (!) the latency you have. You may wonder what happened with benchmarks we showed above after we added MaxFlushDelay option. In Centrifugo we chose default value 100 microseconds, and here are results on localhost (old without delay, new with delay):
> benchstat rueidis_p128.txt rueidis_delay_p128.txt
name old time/op new time/op delta
RedisPublish-8 559ns ± 1% 468ns ± 0% -16.35% (p=0.000 n=9+8)
RedisPublish_History-8 9.72µs ± 1% 9.67µs ± 1% -0.52% (p=0.007 n=9+8)
RedisSubscribe-8 1.45µs ± 1% 1.27µs ± 1% -12.49% (p=0.000 n=9+10)
RedisRecover-8 6.25µs ± 1% 5.85µs ± 0% -6.32% (p=0.000 n=10+10)
RedisAddPresence-8 3.60µs ± 1% 3.33µs ± 1% -7.52% (p=0.000 n=10+10)
(rest is not important here...)
It's even better for this set of benchmarks. Though while it's better for these benchmarks the numbers may differ for other under different conditions. For example, in the benchmarks we run we use concurrency 128, if we reduce concurrency we will notice reduced throughput – as batches Rueidis collects become smaller. Smaller batches + some delay to collect = less requests per second to send.
The problem is that the value to pause Rueidis write loop is a very use case specific, it's pretty hard to provide a reasonable default for it. Depending on request rate/size, network latency etc. you may choose a larger or smaller delay. In v4.1.0 we start with hardcoded 100 microsecond MaxFlushDelay which seems sufficient for most use cases and showed good results in the benchmarks - though possibly we will have to make it tunable later.
To check that Centrifugo benchmarks also utilize less CPU I added rate limiter (50k rps per second) to benchmarks and compared version without MaxFlushDelay and with 100 microsecond MaxFlushDelay:
| 50k req per second | Without delay | With 100mks delay |
|---|---|---|
| BenchmarkPublish | Centrifugo - 75%, Redis - 24% | Centrifugo - 44%, Redis - 9% |
| BenchmarkPublish_History | Centrifugo - 80% , Redis - 67% | Centrifugo - 55%, Redis - 50% |
| BenchmarkSubscribe | Centrifugo - 80%, Redis - 30% | Centrifugo - 45% , Redis - 14% |
| BenchmarkRecover | Centrifugo - 84%, Redis - 51% | Centrifugo - 51%, Redis - 36% |
| BenchmarkPresence | Centrifugo - 114%, Redis - 69% | Centrifugo - 90%, Redis - 60% |
In this test I replaced BenchmarkAddPresence with BenchmarkPresence (get information about all online subscribers in channel) to also make sure we have CPU reduction when using read-intensive method, i.e. when Redis response is reasonably large.
We observe a notable CPU usage improvement here.
Hope you understand now why increasing numPipelineWorkers value in the pipelining code showed before results into increased CPU usage on app and Redis sides – due to smaller batch sizes and more read/write system calls as the consequence.
BTW, would it be a nice thing if Go benchmarking suite could show a CPU usage of the process in addition to time and alloc stats? 🤔
Adding latency
The last thing to check is how new implementation works upon increased RTT between application and Redis. To add artificial latency on localhost on Linux one can use tc tool as shown here by Daniel Stenberg. But I am on MacOS so the simplest way I found was using Shopify/toxiproxy. Sth like running a server:
toxyproxy-server
And then in another terminal I used toxiproxy-cli to create toxic Redis proxy with additional latency on port 26379:
toxiproxy-cli create -l localhost:26379 -u localhost:6379 toxic_redis
toxiproxy-cli toxic add -t latency -a latency=5 toxic_redis
The benchmark results are (old is Redigo-based, new is Rueidis-based):
> benchstat redigo_latency_p128.txt rueidis_delay_latency_p128.txt
name old time/op new time/op delta
RedisPublish-8 31.5µs ± 1% 5.6µs ± 3% -82.26% (p=0.000 n=9+10)
RedisPublish_History-8 62.8µs ± 3% 10.6µs ± 4% -83.05% (p=0.000 n=10+10)
RedisSubscribe-8 1.52µs ± 5% 6.05µs ± 8% +298.70% (p=0.000 n=8+10)
RedisRecover-8 48.3µs ± 3% 7.3µs ± 4% -84.80% (p=0.000 n=10+10)
RedisAddPresence-8 52.3µs ± 4% 5.8µs ± 2% -88.94% (p=0.000 n=10+10)
(rest is not important here...)
We see that new Engine implementation behaves much better for most cases. But what happened to Subscribe operation? It did not change at all in Redigo case – the same performance as if there is no additional latency involved!
Turned out that when we call Subscribe in Redigo case, Redigo only flushes data to the network without waiting synchronously for subscribe result.
It makes sense in general and we can listen to subscribe notifications asynchronously, but in Centrifugo we relied on the returned error thinking that it includes succesful subscription result from Redis - meaning that we already subscribed to a channel at that point. And this could theoretically lead to some rare bugs in Centrifugo.
Rueidis library waits for subscribe response. So here the behavior of rueidis while differs from redigo in terms of throughput under increased latency just fits Centrifugo better in terms of behavior. So we go with it.
Conclusion
Migrating from Redigo to Rueidis library was not just a task of rewriting code, we had to carefully test various aspects of Redis Engine behaviour – latency, throughput, CPU utilization of application, and even CPU utilization of Redis itself under the equal application load conditions.
I think that we will find more projects in Go ecosystem using rueidis library shortly. Not just because of its allocation efficiency and out-of-the-box throughput, but also due to a convenient type-safe command API.
For most Centrifugo users this migration means more efficient CPU usage as new implementation allocates less memory (less work to allocate and less strain on GC) and we tried to find a reasonable batch size to reduce the number of system calls for common operations. While latency and throughput of single Centrifugo node should be better as we make concurrent Redis calls from many goroutines.
Hopefully readers will learn some tips from this post which can help to achieve effective communication with Redis from Go or another programming language.
A few key takeaways:
- Redis pipelining may increase throughput and reduce latency, it can also reduce CPU utilization of Redis
- Don't blindly trust Go benchmark numbers but also think about CPU effect of changes you made (sometimes of the external system also)
- Reduce the number of system calls to decrease CPU utilization
- Everything is a trade-off – latency or resource usage? Your own WebSocket server or Centrifugo?
- Don't rely on someone's else benchmarks, including those published here. Measure for your own use case. Take into account your load profile, paralellism, network latency, data size, etc.
P.S. One thing worth mentioning and which may be helpful for someone is that during our comparison experiments we discovered that Redis 7 has a major latency increase compared to Redis 6 when executing Lua scripts. So if you have performance sensitive code with Lua scripts take a look at this Redis issue. With the help of Redis developers some things already improved in unstable Redis branch, hopefully that issue will be closed at the time you read this post.